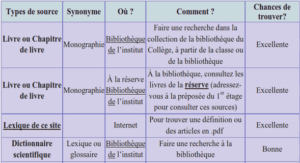
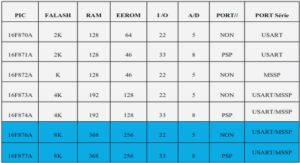
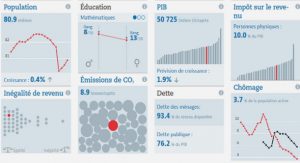
Imprécision et mesure de probabilité
L’imprécision et l’incertitude sont deux aspects de l’imperfection d’une information.Si ces deux aspects peuvent être facilement dissociés dans le langage courant, cette dissociation s’avère plus difficile lorsqu’il s’agit de les représenter à l’aide de la théorie des probabilités. Ce fut une des motivations qui a promut l’émergence de nouvelles théories de représentation d’un défaut de connaissance sur une information. On appelle incertitude un défaut équivalent à un doute sur la validité d’une connaissance. L’incertitude peut provenir d’un manque de fiabilité de l’intermédiaire d’observation, ce dernier pouvant commettre des erreurs intentionnellement ou non. L’incertitude caractérise aussi la difficulté, pour un utilisateur, à vérifier la pertinence ou la véracité d’une information. Par opposition, on appelle imprécision un défaut équivalent à une difficulté d’énoncé de la connaissance disponible sur une information. L’imprécision peut venir d’un défaut d’observation (par exemple 15000 à 20000 manifestants), d’une erreur systématique due à l’étalonnage d’un appareil de mesure (±0, 1◦C) ou encore à l’énoncé d’une connaissance approximative (prix du carburant dans une région). L’imprécision peut aussi venir d’une connaissance vague énoncée en langage familier (ça coûte cher, c’est loin,…)[36]. Fondamentalement, la théorie des probabilités est plutôt dédiée à la gestion des incertitudes tandis que les défauts d’imprécision sont traditionnellement représentés de façon ensembliste (par exemple par l’utilisation d’intervalles de précision) donnant lieu à ce qu’on appelle traditionnellement le calcul d’erreur. Notons qu’il est possible de représenter, via la théorie de probabilités, un défaut d’imprécision par l’intermédiaire des intervalles de confiance [10]. Une dissymétrie fondamentale existe entre ces deux représentations qui est que l’une est nuancée (les probabilités) alors que l’autre est binaire car de nature ensembliste (le calcul d’erreur). L’apparition de la théorie des sous-ensembles flous, introduite par Zadeh à partir de 1965 [127], qui propose une généralisation pondérée de la théorie des ensembles, a permis d’introduire des nuances dans le calcul d’erreur par le biais du principe d’extension. La théorie des sous-ensembles flous est un outil mathématique qui définit le concept d’appartenance partielle à un ensemble.
Mesure de probabilité imprécise et données imprécises
Dans de nombreuses expériences les observations sont des valeurs réelles supposées précises (taille, poids, . . .). Lorsque l’issue d’une expérimentation n’est pas une valeur réelle, son traitement statistique est rendu plus aisé en associant, à chaque issue de l’expérimentation, une valeur réelle. Cette association est appelée variable aléatoire (classique). Une variable aléatoire précise est un nombre réel associé au résultat d’une épreuve. Comme le fait remarquer Kwakernaak [64], lorsque les observations sont imprécises une façon de prendre en compte cette imprécision est d’associer, à chaque résultat d’une expérience aléatoire, un nombre flou plutôt qu’un nombre précis. Cette association porte alors le nom de variable aléatoire floue (VAF) . En d’autres termes, une variable aléatoire floue, d’après Kwakernaak [64], est une généralisation au flou d’une variable aléatoire classique [103, 16]. Dans la même optique, Puri et Ralescu [87], voient une variable aléatoire floue comme une généralisation au flou d’un ensemble aléatoire [103, 49]. Une variable aléatoire floue, d’après Viertl et Trutschnig [120], induit une distribution de probabilité floue. Trutschnig a proposé dans [114] d’estimer cette probabilité floue par un histogramme flou. Ce dernier, d’après Trutschnig [114], est une extension au flou de l’histogramme classique en s’appuyant sur les coupes de niveau. Dans la même optique, Viertl [118, 117] définit une densité de probabilité floue à partir d’une procédure d’intégrale floue. Cette densité de probabilité floue induit, d’après Viertl [117], une distribution de probabilité floue. Dans ce contexte, Arefi et al. ont proposé dans [2] une extension au flou de trois méthodes d’estimation non-paramétrique classiques, présentées en section I.2, d’une densité de probabilité sous-jasente à un ensemble fini d’observations floues. Cette extension se base sur l’utilisation d’une décomposition par coupe de niveau. Nous présentons, dans cette section, deux visions du même concept de variable aléatoire floue : la première est proposée par Puri et Ralescu [87] et la deuxième est issue des travaux de Kwakernaak [64] puis Kruse et Meyer [63]. Nous présentons ensuite le concept d’un histogramme flou au sens de Viertl et Trutschnig [120] ainsi que le concept de distribution de probabilité floue. En ce sens, un histogramme flou, d’après Trutschnig [114], peut être vu comme un estimateur d’une distribution de probabilité floue quand le nombre d’observations floues tend vers l’infini. Nous présentons, à la fin de cette section, l’extension au flou de trois méthodes d’estimation non-paramétrique (classique) proposées par Arefi et al. [2].
Mesure de probabilité imprécise et données précise
Il peut exister des cas où la connaissance que l’on a de la probabilité sous-jascente à un ensemble fini d’observations est imprécise alors que les observations sont précises. En effet, en estimation non-paramétrique, l’estimation de la densité en un point revient à estimer cette densité dans le voisinage de ce point. Par exemple, avec la méthode d’estimation de Parzen-Rosenblatt, présentée en section I.2.3, le noyau sommatif κ (I.8) détermine la forme du voisinage autour de point x ∈ Ω et sa largeur de bande ∆ contrôle la taille de ce voisinage, c’est-à-dire le nombre d’observations prises pour effectuer la moyenne locale. Dans la plupart du temps, le voisinage nécessaire à l’estimation est mal défini ou mal connu. Par exemple, avec la méthode d’estimation par noyau, le noyau d’Epanechnikov (I.32) est le plus utilisé parce que ce noyau minimise le critère AMISE (la distance entre la densité estimée et la vraie densité). Ce noyau peut être changé, en utilisant un autre critère de minimisation comme l’ont proposé Devroy et Lugosi [27, 28]. Généralement, dans beaucoup de domaines d’applications, les noyaux sommatifs et leur largeur de bande sont choisis de façon très empirique. Le caractère empirique du choix du noyau pouvait être pris en compte, d’après [72], en remplaçant un noyau par une famille de noyaux. Cette famille de noyaux peut être représentée par un noyau nonsommatif (ou noyau flou) appelé noyau maxitif. Un noyau maxitif représente l’ensemble des noyaux sommatifs qu’il domine [72]. Dans beaucoup de domaines d’applications, généralement, les noyaux sommatifs et leur largeur de bande sont choisis de façon très empirique. Comme le proposent Loquin et Strauss [72] le caractère empirique du choix du noyau pouvait être pris en compte en remplaçant un noyau par une famille de noyaux. Cette famille de noyaux peut être représentée par un noyau non-sommatif (ou noyau flou) appelé noyau maxitif. Un noyau maxitif représente l’ensemble des noyaux sommatifs qu’il domine [72]. En s’appuyant sur ces types de noyaux non-sommatifs, Loquin et Strauss proposent dans [72] d’étendre l’opérateur espérance sommative (I.9), en parlant de l’espérance maxitive. Cette espérance forme la base de l’estimation maxitive de la fonction de répartition proposée par Loquin et Strauss [71]. Nous présentons, dans cette section, la définition des noyaux maxitifs ainsi que leurs propriétés. Nous introduisons ensuite l’opérateur d’espérance maxitive basé sur un noyau maxitif. Nous nous concentrons sur le principe et la définition de l’estimation imprécise de la fonction de répartition ainsi que sur ses propriétés. Cette estimation représente une étape majeure dans la construction de l’extension maxitive de la densité de probabilité que nous proposons. Nous abordons, à la fin de cette section, la question de l’existence d’une extension maxitive de la densité sous-jascente à un ensemble fini d’observations.
Conclusion générale
Les méthodes d’estimations non-paramétriques habituellement employées dans la littérature utilisent des techniques additives (distribution de probabilité) pour estimer une densité de probabilité sous-jacente à un ensemble fini d’observations. Le travail présenté dans ce mémoire propose de résoudre en partie ce problème en remplaçant l’estimation ponctuelle par une estimation intervalliste de probabilité. Cette estimation est en fait une enveloppe convexe d’un ensemble d’estimations de Parzen-Rosenblatt obtenues à l’aide d’une famille particulière de noyaux sommatifs. Cette méthode d’estimation imprécise de la densité est basée essentiellement sur une extension imprécise de la fonction de répartition développée par Loquin et Strauss [71]. Dans cette méthode, la borne inférieure (rsp. supérieure) de l’intervalle d’estimation de la fonction de répartition est obtenue via l’intégrale de Choquet de la fonction de répartition empirique En par rapport à une mesure de nécessité (rsp. possibilité) induite par un noyau maxitif [71]. Cette extension n’est pas directement applicable à l’estimation de la fonction de densité.Nous proposons, dans ce mémoire, d’utiliser le lien entre la mesure empirique en et la fonction de répartition empirique En (en est la dérivée, au sens de distribution, de En) pour bâtir directement un estimateur imprécis de la densité. Pour réaliser cette estimation, nous avons commencé par reformuler l’estimateur à noyau. Nous avons relié cette reformulation à la théorie de distribution de Schwartz [98], nous permettant ainsi de reformuler l’estimateur de densité comme une combinaison linéaire de deux estimations de la fonction de répartition. L’extension intervalliste de cet estimateur devient alors trivial en se basant sur le travaux de Loquin et Strauss [71]. Nous avons proposé trois extensions différentes permettant de prendre en considération des particularités des noyaux utilisés. Nous avons donné des algorithmes pratique de calcul exact de ces estimations.
|
Table des matières
Introduction générale
I Estimation précise de probabilité
Introduction
I.1 Rappels sur la théorie de la mesure
I.2 Estimation non-paramétrique de densité de probabilité
I.2.1 Estimation naturelle de densité par les histogrammes
I.2.1.1 Histogramme
I.2.1.2 Relation entre densité de probabilité et histogramme des données
I.2.1.3 Estimateur de densité par histogramme
I.2.1.4 Propriétés statistiques de l’estimateur par histogramme
I.2.1.5 Utilisation de l’estimateur de densité par histogrammes
I.2.2 Estimateur simple de densité
I.2.3 Estimateur à noyau de la densité
I.2.3.1 Principe et définition
I.2.3.2 Propriétés statistiques de l’estimateur à noyau
I.2.3.3 Utilisation de l’estimateur de densité par noyau
I.3 Estimation non-paramétrique de la fonction de répartition
I.3.1 Estimation naturelle de la fonction de répartition par la fonction de répartition empirique
I.3.2 Estimation par noyau de la fonction de répartition
II Imprécision et mesure de probabilité
Introduction
II.1 Quelques rappels
II.1.1 Sous-ensembles flous
II.1.2 Mesures de confiances non-additives
II.1.2.1 Capacité
II.1.2.2 Intégrale de Choquet et espérance imprécise
II.1.2.3 Ensembles de probabilités
II.1.2.4 Théorie des fonctions de croyance
II.1.2.5 Théorie de possibilités
II.2 Mesure de probabilité imprécise et données imprécises
II.2.1 Variables aléatoires floues
II.2.2 Histogramme flou et distribution de probabilité floue
II.2.2.1 Histogrammes flous
II.2.2.2 Distribution de probabilité floue
II.2.3 Estimation floue de densité
II.3 Mesure de probabilité imprécise et données précise
II.3.1 Noyaux maxitifs
II.3.2 Espérance mathématique maxitive
II.3.3 Estimation imprécise de la fonction de répartition
II.3.3.1 Principe et définition
II.3.3.2 Propriétés
II.3.4 Peut-on estimer la densité de probabilité par noyau maxitif ?
III Estimation maxitive de densité de probabilité
Introduction
III.1 Reformulation de l’estimateur de densité de Parzen-Rosenblatt
III.1.1 Mesure empirique et estimateur de densité de Parzen-Rosenblatt
III.1.2 Dérivation des distributions et estimateur de densité de ParzenRosenblatt
III.1.3 Décomposition de la dérivée des noyaux sommatifs
III.1.4 Dérivée de noyau et estimateur de densité de Parzen-Rosenblatt
III.1.4.1 Estimateur de densité de Parzen-Rosenblatt
III.1.4.2 Estimateur de densité de Parzen-Rosenblatt : les deux noyaux de la décomposition sont symétriques et issus de la translation d’un même noyau sommatif
III.1.4.3 Estimateur de densité de Parzen-Rosenblatt : cas où le noyau est simplement symétrique
III.2 Estimation maxitive de la densité
III.2.1 Principe et définition de l’estimation maxitive de la densité
III.2.2 Algorithme de calcul de bornes de l’estimation maxitive de la densité
III.2.3 Relation entre estimation maxitive et estimation sommative de la densité
III.2.4 Convergence de l’estimation maxitive de la densité
III.2.4.1 Imprécision de l’intervalle d’estimation de la densité
III.2.4.2 Convergence en un certain sens
III.2.4.3 Comment expérimenter la convergence d’une estimation imprécise de la densité ?
III.3 Spécificité de l’estimation maxitive de la densité
III.3.1 Première restriction sur l’intervalle d’estimation
III.3.2 Deuxième restriction sur l’intervalle d’estimation
IV Expérimentations
IV.1 Décomposition sommative d’un noyau et domination de cette décomposition
IV.1.1 Cas où le noyau est quelconque
IV.1.2 Cas où le noyau est simplement symétrique
IV.1.3 Cas où les deux noyaux de la décomposition peuvent être déduits l’un de l’autre par simple translation
IV.2 Etude expérimentale de l’estimation imprécise de la densité
IV.2.1 Estimation précise et imprécise de la densité : cas général
IV.2.2 Estimation précise et imprécise de la densité : cas particuliers
IV.2.3 Intégrale de l’imprécision de l’estimation imprécise de la densité
IV.2.4 Caractérisation empirique de l’estimation imprécise de la densité
IV.2.5 Inclusions de la densité convoluée dans l’estimation imprécise de la densité : cas général
IV.2.6 Lien entre la variance de l’estimation précise et l’imprécision de l’estimation imprécise
Conclusion générale
Bibliographie
![]() Télécharger le rapport complet
Télécharger le rapport complet