Télécharger le fichier pdf d’un mémoire de fin d’études
Approches exploitant des ressources lexicales et/ou le webKIM
Le système KIM [PKK+04] a pour objectif d’annoter automatiquement les entités nommées dans les documents. Il se base sur les ressources suivantes :
• une ontologie généraliste appelée PROTON, qui définit des concepts, des relations, des attributs et des axiomes ;
• une base de connaissances décrivant des instances dans le vocabulaire de l’ontologie PROTON. Chaque entité y est éventuellement décrite par un ensemble de noms alternatifs appelés alias (exemple : New York, N.Y )
• des ressources lexicales permettant de reconnaître une nouvelle EN, telles que des listes de noms et de prénoms de personnes, des préfixes ou suffixes (exemple : company, SA), ou des devises.
L’objectif de l’approche est d’annoter sémantiquement des entités nommées trouvées dans un document qui existent déjà dans la base de connaissances ou sont nouvelles. KIM extrait les EN en utilisant les outils de la plate-forme GATE [CGW95] et annote chacune des EN extraite du texte par le concept le plus spécifique de l’ontologie auquel l’instance décrite appartient (exemple : le concept Sea pour l’EN Arabian Sea) ainsi que par un lien vers l’instance de la base de connaissances, si cette instance existe déjà. Les annotations résultats sont représentées en RDF. La base de connaissances contient environ 200 000 instances et comprend des lieux tels que les continents, les pays, les villes de plus de 100 000 habitants, ou les rivières ainsi que leurs coordonnées géographiques, les entreprises et organisations les plus connues (exemples : Apple, NATO, OPEC). Les auteurs indiquent que ce type de base de connaissances peut toujours être peuplée avec des connaissances provenant de sources de références et que l’on ne peut extraire d’EN sur la base de l’ontologie seule.
Si l’EN extraite est nouvelle, celle-ci est conservée dans la base de connaissances et peut être utilisée pour de futures annotations sémantiques.
Armadillo
Armadillo [CCDW04] est un système d’annotation non supervisé qui peut aussi bien annoter des documents en utilisant une ontologie de domaine que créer une base de connaissances à partir de différentes entrepôts d’informations. Armadillo utilise des concepts ”ancres”, qui servent d’accroche pour trouver les instances du concept recherché, et des concepts ”annexes”, qui permettent de valider la classification des instances repérées.
Prenons l’exemple où des instances du concept Professor sont recherchées. Le concept Person, un super-concept de Professor, peut être un concept ”ancre” qui possède des instances qui sont facilement repérables dans le texte. En revanche, le concept Person est ambigu. Il peut être désambiguïsé en utilisant les relations de ses instances avec des instances de concepts ”annexes”, comme University ou Article, sur lesquelles il y a peu d’ambiguïté.
L’idée maîtresse dans Armadillo est d’utiliser tout d’abord des informations certaines obtenues sur des instances, par exemple ici, des listes d’universités. Ces instances sont alors recherchées dans les documents, les instances candidates du concept ”ancre” (ici, des noms de personne) sont extraites (par des techniques de détection d’entités nommées). Ensuite, les relations entre les instances candidates du concept ”ancre” et les instances des concepts ”annexes” sont vérifiées, en utilisant :
• la redondance de l’information sur le web. Plus il y a de documents présentant une co-occurrence des instances des concepts ”ancre” et ”annexes”, plus la relation entre eux est probable ;
• certaines techniques, dépendantes du domaine, permettent de vérifier la nature d’une relation entre une instance du concept ”annexe” et une instance du concept ”ancre”. Par exemple, l’utilisation de DBLP 3 permet de trouver des instances d’Article et de Person reliées par la relation auteur. D’autres concepts ”annexes” permettent d’apporter des indices supplémentaires sur la classification d’une instance du superconcept du concept recherché comme étant une instance du concept recherché. Par exemple, la recherche de titres académiques Phd, comme concept ”annexe”, apporte un indice supplémentaire sur la classification d’une personne en tant que professeur. Si les différents indices recueillis sont suffisamment nombreux et/ou sûrs pour reconnaître une instance du concept recherché, cette instance est alors annotée.
Langages de représentation et d’interrogation de ressources Web
Dans cette section nous présentons brièvement les langages de représentation de ressources RDF, RDFS, OWL et SKOS recommandés par le W3C et le langage d’interrogation SPARQL pour le Web Sémantique.
Pile du Web sémantique
D’après la vision de Tim Berners-Lee du Web sémantique, l’information pourra être accessible et compréhensible non seulement par les humains mais aussi par les machines. Dans cette vision, le Web sémantique peut être considéré comme une pile de langages représentée dans la figure 1.1. Cette pile distingue principalement des langages dédiés à la structuration des ressources Web (XML, XML Schema) et la représentation de la sé- mantique qui peut être associée à ces ressources décrites par des ontologies et des règles logiques. La pile est structurée sur trois niveaux principaux [BL98] :
• Niveau d’adressage et de nommage. Ce niveau est représenté par le standard d’adressage des ressources du Web URI (Universal Resource Identifier) et la norme Unicode pour le codage des caractères.
• Niveau syntaxique. Ce niveau syntaxique est représenté par la définition des espaces de noms qui permettent d’identifier les ressources du Web, le langage XML, XML schéma et le langage de requêtes XML Query.
• Niveau Sémantique. Ce niveau est représenté d’une part par les langages de représentation d’ontologies RDF/RDFS et OWL, et d’autre part par les langages de règles, de logique, de preuves et de confiance (trust).
Les langages du Web doivent permettre de :
• décrire les données, les schémas et leur sémantique (RDF/S et OWL) ;
• échanger des métadonnées et des schémas (eXtensible Markup Language / Schema ou XML/S) ;
• interroger les documents par les annotations (SPARQL).
Ontology Web Langage (OWL)
Le niveau d’expressivité du langage RDFS est insuffisant pour représenter des ontologies riches et complexes. OWL étend le langage RDFS pour exprimer des contraintes sur des classes et des propriétés. Par exemple on peut exprimer :
• des contraintes de cardinalité sur les valeurs ou le type d’une propriété : owl :minCardinality, owl :maxCardinality ;
• des propriétés fonctionnelles ou inverses fonctionnelles : owl :FunctionalProperty et InverseFunctionalProperty, symétriques owl :SymmetricProperty, transitives TransitiveProperty ;
• des contraintes de cohérence entre classes : équivalence owl :equivalentClass, disjonction owl :disjointWith ;
• des contraintes de mise en correspondance entre instances owl :sameAs et owl :differentFrom ;
• de nouveaux constructeurs à partir de classes existantes par intersection owl :intersectionOf, union owl :unionOf ou complément owl :complementOf.
Selon son niveau d’expressivité, OWL est décomposé en trois familles de langages :
• Le langage OWL Lite permet de définir une hiérarchie de classes et des contraintes simples. Par exemple, bien que le langage gère les contraintes de cardinalité, il n’admet que les valeurs de cardinalité 0 ou 1. Les constructeurs tels que owl :unionOf, owl :intersectionOf ne font pas partie de OWL Lite.
• Le langage OWL DL, dont le nom est hérité des logiques de description, est l’un des nombreux sous-ensembles décidables de OWL. Il Le niveau d’expressivité de OWL DL garantit la complétude et la décidabilité des algorithmes de raisonnement. OWL DL étend OWL Lite, il permet par exemple l’utilisation des contraintes de cardinalité autre que 0 et 1 et de constructeurs comme owl :disjointWith. Par ailleurs OWL DL nécéssite une séparation entre classes et instances, entre owl :DataTypeProperty et owl :ObjectProperty. De même, des contraintes ne peuvent pas être définies sur des propriétés transitives ou leurs inverses.
• Le langage OWL Full est destiné aux utilisateurs voulant une expressivité maximale. Le raisonnement dans ce cas est incomplet ou non décidable.
Ontologie à composante lexicale
Définitions
Une ontologie est une formalisation explicite d’une conceptualisation commune et partagée [Gru93].
Dans notre travail, l’ontologie que l’on considère est définie par un ensemble de concepts, de relations entre ces concepts et de propriétés. Elle est à composante lexicale [RTAG07], chaque concept est caractérisé par un ensemble de labels et un ensemble de termes. Ce lexique est enrichi par le module SHIRI-Extract. Plus formellement, soit O(CO, RO, ≼ , SO, XO, Lex O ) l’ontologie de domaine où :
• CO est l’ensemble des concepts,
• RO est l’ensemble des relations entre les instances de concepts,
• ≼ désigne la relation de subsomption entre les concepts et entre les relations,
• SO définit le domaine et le co-domaine (signature) de chaque relation,
• XO est l’ensemble d’axiomes du domaine définis sur les concepts et les relations,
• Lex O (L, T , prefLabel, altLabel, hasT erm, hasT ermNe) définit :
• L est l’ensemble des labels de concepts. L’ensemble des labels d’un concept est un ensemble de termes considérés comme équivalents (synonymie dans le domaine) pour représenter un concept.
• T est l’ensemble des termes et entités nommées décrivant les instances des concepts du domaine. L’ensemble des termes d’un concept est un ensemble de termes plus spécifiques que les labels.
• Chaque concept c ∈ CO est lié à un label préféré l ∈ L via la propriété prefLabel 6 et aux labels alternatifs l′ ∈ L via la propriété altLabel7.
• Chaque concept c ∈ CO est relié à un terme via la propriété hasT erm et à une entité nommée via la propriété hasT ermNe. En effet, un terme candidat peut être extrait soit par un pattern spécifique pour les entités nommées soit par un pattern pour les termes.
L’ontologie que notre système exploite pour l’annotation ne décrit que les relations qui ont comme co-domaine des concepts et non des littéraux. Si l’ontologie fournie par l’expert comporte de telles relations (attributs), nous transformons ce littéral en concept car notre approche ne cherche à repérer que des instances de concepts décrits par des labels, des termes ou entités nommées.
Dans notre approche, les ensembles L et T sont respectivement initialisés par un ensemble de labels et un ensemble de termes choisis par l’expert du domaine en utilisant, par exemple, WordNet.
L’ensemble T est automatiquement enrichi par le module SHIRI-Extract. L’ensemble L n’est enrichi que manuellement par l’expert qui valide les termes en modifiant ou en supprimant certains ou en les associant à un concept .
Le concept PartOfSpeech
Comme souligné plus haut, les termes et les ENs relatifs aux concepts ontologiques sont souvent noyés dans les parties non structurées et sont ainsi difficiles à repérer. Un nœud de document peut comporter des termes et des ENs de concepts différents. Le concept P artOfSpeech est défini pour annoter un nœud de document dont le texte contient plusieurs termes ou ENs alignés avec des concepts différents. Une instance de type P artOfSpeech est reliée via la propriété isIndexedBy aux concepts des termes ou ENs repérés dans ce nœud.
Prenons l’exemple d’un nœud contenant le texte ”ECAI 2008, the 18th conference in this series, is jointly organized by the European coordinating Committee on Artificial Intelligence the university of Patras and the Hellenic Artificial Intelligence Society” où des termes ou EN alignés avec les concepts Date (date), T opic (thème), Event (événement) et Location (lieu) sont localisés. Ce nœud est donc annoté comme instance du concept P artOfSpeech et est reliée via la propriété isIndexedBy aux concepts Date, T opic, Event et Location.
Le concept SetOfConcept
Avant de définir les métadonnées SetOfConcept et ses concepts descendants SetOfc, nous définissons les concepts comparables.
Concepts comparables : C un est ensemble de concepts comparables si ∀ci ∈ C et ∀cj ∈ C, subClassOf(ci, cj) ∨ subClassOf(cj, ci). Un exemple de concepts comparables est représenté dans la figure 2.6.
Un nœud de document, comportant des termes ou ENs de concepts comparables appartenant à un ensemble C de concepts comparables, est annoté comme une instance de SetOfc tel que c est le concept ancêtre des concepts de C.
Par exemple, le concept ontologique T opic défini dans 2.1 est relié via la propriété hasSet au concept SetOfT opic qui est un sous-concept direct de SetOfConcept. Le nœud contenant le texte « searching, querying, visualizing, navigating and browsing the semantic web », où plusieurs termes du concept T opic sont localisées, est annoté par SetOfT opic.
Un autre exemple de nœud où plusieurs entités nommées de concepts comparables scientist et son super-concept P erson sont repérés dans le texte, ce nœud est annoté en tant qu’instance de SetOfP erson.
La propriété neighborOf
Vu l’hétérogénéité des documents, l’extraction des relations du domaine peut s’avérer encore plus difficile que pour les instances de concepts. Le principe de notre approche est d’utiliser les nœuds annotés, leur sémantique et leur proximité structurelle pour déduire une relation entre instances, plus précisément, entre nœuds.
Le voisinage structurel est représenté par le chemin de liens entre nœuds de l’arbre structurel DOM du document.
La relation neigbhorOf est instanciée pour deux nœuds de type Metadata reliés par un chemin structurel de longueur ne dépassant pas une valeur déterminée d. Les deux nœuds doivent contenir respectivement des instances de concepts ci et cj ∈ CO tels que ∃r ∈ RO où ci ∈ domaine(r) et cj ∈ co–domaine(r). Cette relation est symétrique.
La relation neighborOf est instanciée quand la distance est nulle. Dans ce cas, les instances se trouvent dans le même nœud et ce nœud est de type P artOfSpeech.
Les métadonnées de pré-annotation
Nous avons également défini deux propriétés de pré-annotation pour représenter les résultats obtenus par le module SHIRI-Extract.
• La propriété containInstanceOf est définie entre un nœud et un concept ci ∈ CO, pour exprimer le type du terme ou de l’entité nommée localisée dans ce nœud.
• De la même manière, la relation hasValueInstance est définie entre un nœud et un littéral pour conserver le terme ou l’entité nommée (littéral) localisé dans ce nœud.
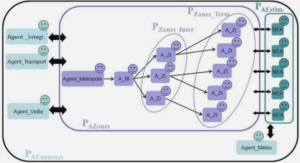
Architecture de notre système
Dans cette section, nous présentons les modules définis dans notre système, à savoir, la constitution du corpus, l’extraction SHIRI-Extract et l’annotation SHIRI-Annot (figure 2.7). Notre système utilise les langages du W3C [W3Ca] : RDF/RDFS pour la représentation du modèle d’annotation et les documents annotés et SPARQL pour leur interrogation.
Constitution du corpus
La constitution du corpus se fait en deux étapes : (i) chargement du corpus portant sur le domaine d’intérêt et (ii) pré-traitement du corpus.
Chargement du corpus
Le chargement du corpus peut se faire automatiquement en utilisant un moteur de recherche comme Google ou Yahoo. Pour ce faire nous identifions un ensemble de mots clé appelés graines (seed en anglais). Ces mots sont combinés pour former des n-uplets qui sont fournis au moteur de recherche pour obtenir une liste d’URLs de documents à télécharger. Ces mots clé sont formés à partir des labels de concepts et éventuellement des termes déjà alignés aux concepts de l’ontologie. Le chargement automatique des documents à partir des sites ainsi identifiés se fait via un crawler (un robot d’indexation) comme montré dans la figure 2.7.
|
Table des matières
Introduction générale
1 Contexte
2 Problématique
3 Contributions
4 Plan du manuscrit
Chapitre 1 ÉTAT DE L’ART
1.1 Extraction et annotation sémantique dans les documents semi-structurés
1.1.1 Approches exploitant la structure des documents
1.1.2 Approches exploitant des patterns syntaxiques ou lexico-syntaxique dans le texte
1.1.3 Approches exploitant des ressources lexicales et/ou le web
1.2 Langages de représentation et d’interrogation de ressources Web
1.2.1 Pile du Web sémantique
1.2.2 Ressource Description Framework / Schema (RDF/RDFS)
1.2.3 Ontology Web Langage (OWL)
1.2.4 Simple Knowledge Organisation Systems (SKOS)
1.2.5 Langage d’interrogation SPARQL
Chapitre 2 PRÉSENTATION DE L’ARCHITECTURE DE NOTRE SYSTÈME
2.1 Ontologie à composante lexicale
2.1.1 Définitions
2.1.2 Exemple
2.2 Modèle d’annotation
2.2.1 Le concept PartOfSpeech
2.2.2 Le concept SetOfConcept
2.2.3 La propriété neighborOf
2.2.4 Les métadonnées de pré-annotation
2.3 Architecture de notre système
2.3.1 Constitution du corpus
2.3.2 Processus d’extraction SHIRI-Extract
2.3.3 Processus d’annotation SHIRI-Annot
2.4 Scénario d’usage
Chapitre 3 EXTRACTION, ALIGNEMENT DES ENTITÉS NOMMÉES ET DES TERMES
3.1 Présentation de SHIRI-Extract
3.1.1 Objectifs généraux
3.1.2 Extraction des termes candidats
3.1.3 Stratégie de sélection des termes candidats
3.1.4 Alignement local ou via le web
3.1.5 Enrichissement de l’ontologie
3.2 Algorithme d’extraction et d’alignement
3.2.1 Notations et principes algorithmiques
3.2.2 Alignement local d’une entité nommée
3.2.3 Alignement local d’un terme
3.2.4 Alignement via le Web d’un terme candidat
3.2.5 Illustration
Chapitre 4 ANNOTATION DES DOCUMENTS ET INTERROGATION
4.1 Règles d’annotation
4.1.1 Notations
4.1.2 Génération du typage des nœuds
4.1.3 Génération de relations de voisinage entre nœuds
4.1.4 Exemple d’application des règles d’annotations
4.2 Interrogation des annotations
4.2.1 Définitions préliminaires
4.2.2 Types de requête utilisateur
4.2.3 SHIRI-Querying
4.3 Conclusion
Chapitre 5 EXPÉRIMENTATIONS ET ÉVALUATION DES RÉSULTATS
5.1 Entrées des expérimentations
5.1.1 Ontologie du domaine
5.1.2 Constitution du corpus
5.2 Expérimentation et évaluation de l’extraction et de l’alignement
5.2.1 Résultats de l’extraction
5.2.2 Outil de Pierre Senellart
5.2.3 Résultats de l’alignement
5.3 Expérimentation et évaluation de l’annotation
5.3.1 Résultats du typage des nœuds
5.3.2 Évaluation de la relation neighborOf selon la distance
CONCLUSIONS ET PERSPECTIVES
1 Apports de notre approche
2 Perspectives
Télécharger le rapport complet