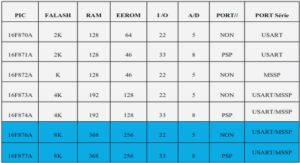
Télécharger le fichier pdf d’un mémoire de fin d’études
Estimation et Apprentissage
Les deux grands domaines auxquels est rattaché ce travail de thèse sont : l’estimation et l’apprentissage.
L’estimation est une branche du domaine des statistiques qui consiste à estimer la valeur des paramètres recherchés à partir de données mesurées entachées de composantes aléatoires [6, 7]. Ces dernières peuvent représenter le bruit de mesures ou bien des phénomènes plus abstraits tels que les erreurs de modélisations.
Dans ce manuscrit, l’objectif principal va être d’obtenir un estimateur de la quantité d’intérêt. Bien que des approches linéaires (chapitre 2) permettent d’obtenir de bons résultats, l’estimateur retenu sera une application non-linéaire (chapitre 3) afin de pouvoir se détacher facilement des contraintes classiques de ce type de problème (wellposedness). Les approches d’estimation à base de parcimonie, sparsity, sont considérées [8, 9, 10, 11].
Les articles [12, 13] ont été le point de départ des travaux de cette thèse.
Cependant, la prise en compte de données statistiques ne sera pas faite de manière conventionnelle (approche probabiliste). L’idée principale étant de produire l’approche la plus générale possible, ne nécessitant aucune intégration complexe d’informations de nature probabiliste sur le bruit pour fonctionner. Après une étude du cas non-bruité, le bruit sera intégré grâce aux capacités d’apprentissage de l’algorithme recherché (section 3.4).
En effet, la nature même des données disponibles, des images de la grandeur d’intérêt (un champ de pression par exemple), donne à ce problème des affinités fortes avec le domaine de l’apprentissage. Dans le contexte présent (traitement de données numériques), ce domaine est plus connu sous le nom de Machine Learning puisque l’apprentissage sera fait de manière algorithmique, par des machines [14, 15]. Ces approches ont pour objectif de traiter, de manière supervisée ou non, des jeux de données afin d’extraire différentes caractéristiques connues ou non. Ce domaine est ainsi très large de par sa nature et regroupe de nombreux problèmes (tout comme les problèmes inverses). Plus d’information sur ce vaste domaine se trouve dans le chapitre 4.
Pour conclure, l’estimateur recherché devra être produit uniquement à partir des jeux de données initiaux. Il doit aussi être capable, de par sa nature, d’inclure des informations sur le bruit de mesure. Sa simplicité d’utilisation doit lui permettre d’être applicable sur de nombreux problèmes sans modifications majeures.
Position du problème
Recherche d’un estimateur
De nombreux domaines tels que la mécanique des fluides, l’étude des machines électriques (branche du génie électrique) et l’étude des déformations de structures massives (branche du génie civil) peuvent voir leurs grandeurs d’intérêts prédites avec grande précision.
En effet, la puissance de calcul des ordinateurs de bureau actuels fait qu’il est possible d’exploiter pleinement les équations différentielles de la physique (équations de Maxwell, de Navier-Stokes, …) à l’aide d’algorithmes exploitant leurs formes discrétisées (spatialement et temporellement). Ces simulations (types éléments finis) produisent ainsi des jeux de données très proches des données observées. Cependant, de telles simulations sont très lourdes et ne peuvent pas être utilisées en temps réel pour obtenir des informations sur le système (en vue d’une commande par exemple). C’est à cette échelle que l’approche recherchée intervient. L’estimateur est produit à partir de ces jeux de données simulés et peut ensuite être utilisé en temps réel (en d’autres termes, l’estimation doit être simple à évaluer numériquement). Cet estimateur exploite les données mesurées (faible dimension) afin d’obtenir une estimée des données sources, des données d’intérêt (grande dimension).
Suivant la nature des données simulées, différents estimateurs seront proposés. Ces derniers seront de plus en plus complexes à synthétiser mais pourront être appliqués à des problèmes plus complexes.
Les estimateurs recherchés doivent être capables de répondre aux contraintes suivantes :
— ils sont produits uniquement à partir des jeux de données initiaux sous format matriciel
— ils n’exploitent aucun a priori physique, aucun modèle d’évolution dynamique
— ils peuvent inclure des données statistiques sur le bruit de mesure
— ils peuvent être utilisés en temps réel
— ils présentent de meilleures performances que les méthodes actuelles.
Choix des mesures
Vu la nature du problème considéré, la position des capteurs joue un rôle primordial.
Les capteurs sont ici des sous-systèmes qui permettent d’obtenir une information sur le système principal étudié.
Dans un premier temps, les capteurs donneront une information locale sur la grandeur à estimer. Le jeu de données mesuré sera une restriction du jeu de données à estimer.
Ceci correspond tout simplement au cas où les mesures sont une restriction du champ à reconstruire.
Ensuite, un cas plus général où les mesures sont faites sur un objet de nature différente, mais tout de même reliées à la grandeur principale à estimer, est considéré (voir les chapitres 3 et 4). Cette différence peut prendre pour origine le fait que les mesures sont bruitées ou qu’elles sont modifiées par la caractéristique entrée-sortie des capteurs utilisés.
Étant donné qu’un nombre limité de mesures est disponible, la question “qu’est-ce qui doit être mesuré ?” doit être traitée avec soin. De ce fait, le second objectif de cette thèse est de produire un algorithme permettant d’effectuer un placement des capteurs adapté à l’estimateur recherché (voir le chapitre 5). Outre la production d’un placement adapté à l’estimation effectuée, cet algorithme devra être capable de prendre en compte efficacement des contraintes de placement. Ceci traduit le fait que les capteurs ne peuvent pas être placés librement à cause de leur extension spatiale non-nulle et/ou des contraintes de fixation des capteurs. Enfin, des informations statistiques sur le bruit de mesure devront aussi être exploitées pour produire des positions robustes.
Avant-propos
Satisfaisant à toutes ces restrictions, une méthode capable de s’adapter à n’importe quel domaine produisant des données numériques discrétisées sera élaborée. Cette méthode sera générale et ne sera pas restreinte à l’application (de nature fluide) utilisée tout au long de ce manuscrit. Elle inclura une approche de placement des capteurs ainsi que la génération d’estimateurs simples à utiliser.
Afin de synthétiser le contenu des différents chapitres et ainsi permettre une lecture plus ciblée, un résumé de chaque chapitre de ce manuscrit est disponible ci-dessous.
Le chapitre 2 a pour objectif d’illustrer le problème retenu. Ce dernier y sera clairement formalisé. Le contexte, les méthodes existantes, le système servant de benchmark, les notations et les diverses hypothèses formulées sont tous disponibles dans ce chapitre.
Le chapitre 3 expose comment la notion de parcimonie a été exploitée pour produire un premier estimateur. Ces pages contiennent toutes les informations qui ont permis de concevoir cet estimateur. Ce dernier est facilement reproductible à l’aide des divers Pseudo-Codes présents et des notes techniques permettant de surmonter quelques problèmes mineurs de convergence ou des cas particuliers. Cet estimateur est ensuite généralisé pour pouvoir être applicable sur plus de problèmes.
Le chapitre 4 exploite la notion de classification (sans oublier la parcimonie) afin d’améliorer l’estimateur général proposé dans le chapitre précédent. Ce chapitre n’est qu’une ébauche de ce qu’il est possible de faire en combinant la parcimonie et la classification.
De nombreuses améliorations peuvent être faites sur chacune des étapes proposées.
Le chapitre 5 est dédié à la résolution d’un problème de placement de capteurs. La nécessité de produire un algorithme dédié est démontrée. Un algorithme flexible capable de s’adapter au contexte de l’étude a été proposé. Ce dernier présente de nombreux avantages qui sont détaillés dans les pages de ce chapitre.
Le chapitre 6 est un recueil d’applications variées. De nouveaux problèmes sont soulevés puis résolus sans difficulté par les algorithmes produits lors de ce travail de thèse.
Ce chapitre a pour objectif d’illustrer le potentiel des méthodes produites. Pour donner un avant goût de ce chapitre, dans un système fluide classique, une mémorisation des commandes appliquées et des mesures a été effectuée pour estimer avec grande précision le champ de pression et la traînée. De plus l’estimation du champ des vitesses a été réalisée à partir de mesures de pressions en surface de l’obstacle seulement.
Le chapitre 7 est la conclusion générale de ce travail. Il contient quelques propositions de travaux de développement, permettant d’améliorer les résultats obtenus.
Système Test
Cette section a pour objectif de décrire un système pratique qui servira de référence tout au long du manuscrit. Un tel système permettra principalement d’illustrer la flexibilité de la formulation précédente et la méthode couramment utilisée pour résoudre ce problème.
L’expérience retenue est l’écoulement d’un fluide autour d’un obstacle solide, un cylindre.
Avant d’expliciter chaque paramètre, un rappel des concepts de base de la mécanique des fluides est donné.
Mécanique des Fluides
La mécanique des fluides traite de l’étude du comportement des fluides et des forces internes associées. On appelle plus communément fluide les liquides et les gaz. Un écoulement de fluide peut être décrit par la connaissance du mouvement de chacune des entités élémentaires le constituant, en général des atomes et/ou des molécules. Cependant, une telle approche fait intervenir un bien trop grand nombre de particules. Par exemple, un volume de 1m3 d’eau liquide contient environ 3.1030 molécules d’eau. Une approche exploitant directement les lois de la mécanique du point sur un système à plusieurs corps est alors déconseillée à cause du nombre d’inconnues (position et vitesse de chaque molécule, d’un point de vue classique). Une description plus macroscopique du fluide est nécessaire pour contourner cet obstacle dû à la dimension. Les paragraphes qui suivent ont pour but de présenter succinctement les notions essentielles de la mécanique des fluides afin de mieux cerner les spécificités du système test.
Particule Fluide
Le concept de particule fluide est indispensable dans les études de ce domaine. Au lieu de considérer chacune des entités élémentaires, un groupement de ces dernières est réalisé afin de former une particule fluide. L’intérêt d’une telle description est de pouvoir y associer des grandeurs macroscopiques, facilitant grandement la description du fluide.
Chaque particule fluide possède par construction une masse élémentaire constante lors de l’écoulement. La vitesse d’une particule fluide est la vitesse d’ensemble (vitesse barycentrique) des molécules qu’elle contient. La pression et la température d’un tel objet peuvent aussi être définies. La validité de cette description dépend de la taille de la particule fluide. Cette taille doit être petite au niveau macroscopique, où les grandeurs d’intérêts sont continues, afin de décrire précisément l’écoulement. Elle doit aussi être grande au niveau microscopique afin de pouvoir négliger les fluctuations associées principalement à l’agitation thermique (par exemple, la température d’une particule élémentaire n’a pas de sens). L’échelle d’étude est qualifiée de mésoscopique.
Pour se faire une idée plus concrète, un écoulement d’eau liquide dans un conduit de 10cm de diamètre est considéré. La longueur caractéristique de cet écoulement est L = 0.1m. La distance moyenne entre deux molécules d’eau est de l’ordre de grandeur du diamètre de cette molécule, soit l = 3.10−10m. La particule fluide est modélisée par un cube d’arête de longueur a. Afin de travailler à l’échelle mésoscopique, a doit vérifier : l a L. Dans ce cas, avec a = 10−6m = 1μm, la particule fluide a une masse dm = 10−15kg, occupe un volume d = 10−18m3 et contient environ 3.1010 particules.
Description Eulérienne et Lagrangienne d’un fluide
Deux descriptions sont couramment utilisées pour décrire le comportement d’un fluide, la description Lagrangienne et Eulérienne.
Dans la description Lagrangienne d’un fluide, les caractéristiques du fluide sont obtenues en suivant chaque particule fluide lors de son mouvement. Ce dernier est décrit par la connaissance des trajectoires Ri (t) = OMi(t), où, O est l’origine du repère euclidien utilisée et Mi(t) repère la ième particule fluide à la date t. La vitesse de ces particules est donnée par V i (t) = dRi(t) dt . Cette description correspond à celle communément utilisée en mécanique du point.
Dans le cadre d’une approche Eulérienne, les caractéristiques du fluide sont déterminées en chaque point fixe de l’espace. Le mouvement du fluide est donné par la connaissance des vitesses des particules fluides passant par tout point M donné de l’espace d’étude à la date t : v (M, t). Ce dernier est un champ vectoriel. Au lieu de suivre une particule fluide dans son mouvement, un seul point M de l’espace est étudié. Il y a ainsi plusieurs particules fluides qui “passent” par M, définissant ainsi la vitesse à l’instant étudié. Ces deux approches sont reliées par : V i (t) = v (Ri (t) , t). Cette description est particulièrement adaptée pour décrire un espace discrétisé où la valeur des champs en chaque point du maillage est étudiée.
Dans la suite, le champ vectoriel des vitesses et le champ scalaire de pression sont principalement utilisés. Dans le cadre Eulérien, la valeur de ces champs au point M à l’instant t est noté v (M, t) et P (M, t).
Lignes de courants
Le pendant de la notion de trajectoire en description Lagrangienne correspond à la notion de ligne de courant en description Eulérienne. Pour un instant donné, une ligne de courant est une courbe telle que le vecteur vitesse d’une particule fluide se situant sur cette dernière y est tangent. La méthode d’obtention de telles courbes est similaires à celle utilisée pour déterminer des lignes de champ électrique ou magnétique. Soit dM(M, t) un élément vectoriel tangent au point M d’une ligne de courant tracé à l’instant t. Cet élément est colinéaire au vecteur vitesse v (M, t). Ceci ce traduit par la relation : dM(M, t) ^ v (M, t) = 0, (2.19) où 0 est le vecteur nul, de dimension appropriée.
|
Table des matières
1 Contexte Scientifique
1.1 Introduction
1.2 Estimation et Apprentissage
1.3 Position du problème
1.4 Avant-propos
2 Illustration du problème
2.1 Mise en équation
2.2 Système Test
2.2.1 Mécanique des Fluides
2.2.2 Description du système
2.2.3 Détermination de l’état du système
2.3 Approche classique
2.3.1 Approche naïve
2.3.2 Approche POD
2.4 Caractérisation des performances
2.4.1 Données
2.4.2 Résultats
2.4.3 Limitations
2.5 Conclusion
3 Exploitation de la Parcimonie
3.1 Les représentations creuses
3.1.1 Outils
3.1.2 Résolution
3.1.3 Compatibilité des bases usuelles
3.2 Création d’une base adaptée au problème
3.2.1 Application directe de la K-SVD
3.2.2 Intégration de la position des capteurs – SOBAL
3.2.3 Résultats
3.3 Généralisation
3.3.1 Goal-Oriented – SOBAL généralisé
3.3.2 Tentative de découplage
3.3.3 GOBAL
3.3.4 Résultats
3.4 Robustesse au bruit de mesure
3.4.1 Modélisation
3.4.2 Dictionnaires robustes
3.4.3 Illustration numérique
3.5 Comportement face à une séquence originale
3.6 Conclusion
4 Parcimonie et Classification
4.1 La classification
4.1.1 Motivations
4.1.2 Approches usuelles
4.2 GOC : Goal-Oriented Classifier
4.2.1 Estimateur simplifié
4.2.2 Algorithme
4.2.3 Résultats
4.3 Classed Based GOBAL – CB.GOBAL
4.3.1 Choix de la structure
4.3.2 Algorithme
4.3.3 Résultats
4.4 Conclusion
5 Placement des capteurs
5.1 Cadre
5.1.1 Approches Usuelles
5.1.2 Limitations
5.2 SensorSpace
5.2.1 Algorithme
5.2.2 Résultats
5.3 Extensions
5.3.1 Robustesse au bruit de mesure
5.3.2 Cas Goal-Oriented
5.3.3 Capteurs pour la classification
5.4 Conclusion
6 Mise en oeuvre pratique
6.1 Exploitation des mesures passées
6.1.1 Extension des mesures
6.1.2 Placement des capteurs et retard
6.1.3 Cas si/si−k
6.1.4 Cas si/si−k1/si−k2
6.2 Exploitation des commandes
6.2.1 Placement des capteurs
6.2.2 Cas si/ui
6.2.3 Cas si/si−ks/ui/ui−ku
6.3 Estimation d’un champ de nature différente
6.3.1 Manipulation de la traînée
6.3.2 Cas synthétique
6.3.3 Estimation du champ des vitesses
6.4 Conclusion
7 Conclusion
7.1 Conclusion Générale
7.2 Poursuite du travail
Télécharger le rapport complet