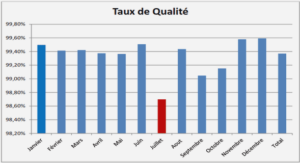
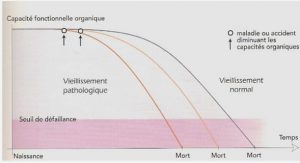
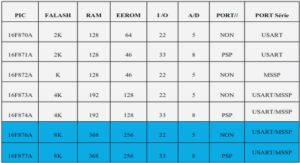
« Quoi de pire que d’être coincé dans les bouchons ? » C’est la question que se posent de nombreux automobilistes sur leur trajet quotidien vers leur travail. Avec l’augmentation du nombre d’automobilistes et la concentration des habitants dans des zones urbaines, la congestion des infrastructures de transport est devenue un problème majeur dans le monde. Au coût économique et de qualité de vie lié au temps perdu par les usagers sur la route s’ajoute le coût écologique lié à la pollution et à la consommation de carburant qui se traduit par des émissions de gaz à effet de serre. Face à ce problème, la mission des gestionnaires d’infrastructures est multiple: informer les usagers des conditions de trafic, anticiper les perturbations et la congestion, et proposer des actions en conséquence pour mitiger voir même résoudre ces problèmes.
Dans les dernières décennies sont apparus de nouveaux outils pour aider les gestionnaires à atteindre ces objectifs : les systèmes de transport intelligents (abrégés ITS en anglais). Ces derniers ont pu voir le jour grâce à l’essor des nouvelles technologies de l’information. Ils intègrent différents composants permettant de surveiller le réseau grâce à des capteurs ou de la vidéo par exemple, de gérer automatiquement certains systèmes comme les feux des carrefours et de fournir de l’information aux usagers, comme les assistants de navigation GPS, en s’appuyant parfois sur des modules prédictifs, pour fournir par exemple des estimations de temps de trajet. Les applications d’assistance à la navigation, comme Waze, permettent de collecter une quantité massive d’information sur les usagers du réseau et fournissent en temps-réel des informations sur l’état du trafic de l’ensemble du réseau. Les données, considérées comme le nouvel or noir, sont un enjeu majeur pour les entreprises, qui s’appuient dessus pour développer de nouveaux produits innovants. La création et la possession de ces données est souvent restreinte à quelques entreprises qui dominent le marché et les revendent aux autres acteurs souhaitant proposer des services autour de la donnée. Avoir la main sur la création et la distribution de la donnée est un enjeu majeur pour les gestionnaires d’infrastructure et plus largement les métropoles qui s’interrogent sur la question de la gouvernance des données.
La Métropole de Lyon a notamment mis en place dans le cadre de sa démarche « Lyon Métropole intelligente » la plateforme Data Grand Lyon qui permet entre autre l’utilisation libre et gratuite (open data) de nombreuses données. Dans le cadre du trafic, la ville continue d’installer de nombreux capteurs sur son réseau de transport afin de pouvoir surveiller en tempsréel son activité et créer une base de données historique. Les données ainsi collectées servent d’entrée à de nombreuses applications, dont la prévision du trafic. On distingue la prévision à long terme (typiquement 24h à l’avance) et la prévision à court terme (typiquement à moins d’une heure). En quelques décennies, cette évolution technologique a considérablement modifié les objectifs dans le domaine de la prévision à court terme. On est passé de l’observation localisée de quelques tronçons d’autoroute à la nécessité de produire des prévisions à l’échelle d’un réseau urbain complet. La méthodologie et les algorithmes utilisés sont donc amenés à évoluer pour répondre à ces nouveaux enjeux .
Une grande diversité de travaux de recherche ont été menés dans ce domaine, s’appuyant sur différentes spécialités comme les approches par simulation, l’étude statistique des séries temporelles, et différents champs de l’apprentissage artificiel, comme l’étude des réseaux de neurones ou des machines à vecteurs support. Les jeux de données étudiés varient également par le système considéré : autoroute, périphériques, grandes villes avec un réseau très structuré (comme le quartier de Manhattan) ou villes avec un centre historique, comme de nombreuses métropoles européennes. Enfin les dimensions des données (nombre de capteurs) et les variables de trafic considérées (vitesse, débit, temps de parcours, trajectoires) s’ajoutent à cette diversité. Il devient ainsi important de pouvoir dégager de cette littérature une connaissance permettant de choisir la méthode la plus appropriée au système que l’on souhaite étudier, en tenant compte de ses spécificités. Un point important pour améliorer la qualité des modèles de prévision réside dans la sélection des variables utilisées pour faire la prévision. Dans le contexte de la prévision de trafic, on dispose généralement de données provenant d’un grand nombre de capteurs et une question délicate est : quels capteurs considérer pour prévoir le futur d’un capteur donné, et à quels horizons temporels ? Pour répondre à cette question, il est possible d’exploiter des connaissances sur la topologie du réseau de transport ou sur le trafic urbain, ou également d’utiliser des méthodes d’apprentissage artificiel.
Notions de probabilités et statistique
Dans cette partie, nous allons introduire les notions de bases en probabilités et statistiques permettant de comprendre les travaux de la thèse. Il est possible de décrire très formellement et dans un cadre très général les concepts appartenant à la théorie des probabilités, mais cela sort du cadre de la thèse. L’objectif est de donner au lecteur l’intuition derrière ces notions, et les outils nécessaires pour comprendre les calculs présentés par la suite.
Probabilités
Variable aléatoire réelle. Une variable aléatoire X est une fonction qui décrit le résultat d’une expérience aléatoire par un nombre réel. Si l’ensemble des valeurs possibles est fini ou infini dénombrable, on parle de variable discrète. Si l’ensemble des valeurs possibles est infini, comme l’ensemble des réels, ou un intervalle sur les réels, on parle de variable continue.
Distribution de probabilité continue. Une distribution (ou loi) de probabilité associe une probabilité aux valeurs que peut prendre une variable aléatoire. Dans le cas d’une variable discrète, on peut associer une probabilité à chacune des valeurs possibles. Dans le cas d’une variable continue, la probabilité que la variable prenne une valeur précise est toujours nulle (car il y en a une infinité). On s’intéresse donc à la probabilité que la valeur appartienne à un certain intervalle.
Fonction de répartition. On peut décrire la loi de probabilité d’une variable aléatoire X, discrète ou continue, par sa fonction de répartition :
F : R → [0, 1]
x → P(X ≤ x)
On peut donc voir que la probabilité que X prenne une valeur dans l’intervalle [a, b] s’exprime de la manière suivante :
P(a ≤ X ≤ b) = F(b) − F(a)
Position et dispersion. On peut parler de l’espérance comme d’un indicateur de position et de la variance comme d’un indicateur de dispersion de la distribution de probabilité suivie par une variable aléatoire.
Pour illustrer, imaginons que la variable X représente la note à un examen d’un élève appartenant à une classe. L’espérance E[X] correspond à la note moyenne que l’on s’attend à observer si l’on considère un grand nombre d’élèves de cette classe. Cela positionne la classe sur l’échelle des notes allant de zéro à vingt. Une autre classe sera représentée par une autre distribution dont l’espérance et la variance seront peut-être différentes. La variance représente l’écart au carré moyen par rapport à la moyenne. C’est donc un indicateur de la dispersion des notes. Plus la variance est faible, plus les notes seront concentrées autour de la moyenne. Plus elle est élevée, plus les notes seront dispersées. Pour résumer notre exemple, l’espérance nous informe sur le niveau moyen de la classe, et nous permet donc de positionner plusieurs classes sur l’axe des notes. La variance permet de caractériser la dispersion des notes autour de la moyenne. Elle nous renseigne donc sur l’homogénéité du niveau des élèves.
Des probabilités aux statistiques
Nous avons jusqu’à présent introduit des notions de probabilités qui permettent de décrire le résultat d’une expérience aléatoire qui se déroule suivant certaines règles fixées et connues. Maintenant, nous allons porter notre attention sur des notions de statistiques. En partant d’un ensemble d’observations du résultat d’une expérience aléatoire, nous souhaitons retrouver les règles qui régissent cette expérience. En d’autres termes, nous souhaitons estimer les caractéristiques de la distribution de probabilités suivie par la variable aléatoire qu’on observe.
Échantillon. On appelle échantillon un ensemble de réalisations d’une variable aléatoire. C’est à partir de cet ensemble d’observations que l’on va tenter d’étudier la distribution de probabilité.
Statistique. Ce paragraphe a pour objectif de présenter une homonymie qui introduit souvent de la confusion chez le lecteur. Les expressions « les statistiques » et « la statistique » font souvent référence au domaine mathématique que l’on vient d’introduire. Mais il existe aussi un concept mathématique bien précis que l’on appelle « une statistique ». Une statistique est le résultat d’un calcul portant sur les valeurs contenues dans un échantillon. Par exemple, si on a observé n fois la variable X, on dispose d’un échantillon de n valeurs (x1, . . . , xn). Le résultat d’un calcul impliquant ces n valeurs est une statistique.
|
Table des matières
1 Introduction Générale
2 Cadre théorique de l’apprentissage supervisé
2.1 Notions de probabilités et statistique
2.1.1 Probabilités
2.1.2 Des probabilités aux statistiques
2.1.3 Relation entre plusieurs variables
2.2 Apprentissage supervisé
2.3 Séries temporelles
2.4 Discussion
3 Introduction à la prévision de trafic
3.1 Approches par modèles de trafic
3.2 Modèles statistiques
3.2.1 Famille des modèles ARIMA
3.2.2 Modèle espace-état
3.3 Méthodes d’apprentissage artificiel
3.3.1 Approches des k plus proches voisins
3.3.2 Méthodes à noyaux
3.3.3 Réseaux de neurones artificiels
3.4 Différentes grilles de lectures
4 Méthodes de prévision
4.1 Régression linéaire
4.2 Régression Ridge
4.3 Régression lasso
4.4 Combinaisons polynomiales de variables
4.5 Régression à vecteurs de support
4.5.1 Cas linéaire
4.5.2 Cas non-linéaire – utilisation du noyau
4.6 Régression k-NN
4.7 ARIMA
4.7.1 Modèle autorégressif AR(p)
4.7.2 Modèle moyenne mobile MA(q)
4.7.3 ARMA(p,q)
4.7.4 ARIMA(p,q,d)
4.8 Modèle Vecteur Autorégressif (VAR(p))
5 Conclusion Générale