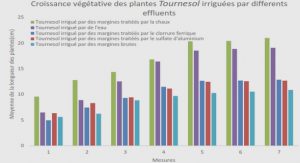
Ordonnancements
Nous avons vu précédemment qu’un système multi-agents est compose par définition de plusieurs agents qui exécutent chacun leur comportement ≪ perception-décision-action ≫ par cycle. Nous allons maintenant détailler l’organisation du temps de calcul des agents au sein d’une simulation. L’ordonnanceur est le programme charge de faire progresser la simulation de l’instant t a l’instant t+1. Il doit également faire évoluer les agents en lançant leur cycle comportemental appelle activité, successivement. Au niveau du système, le cycle correspond `a l’appel unique de l’ensemble des activités. La question de la synchronicité devient cruciale d`es lors qu’on manipule des objets actifs. Pratiquement, nous distinguons deux modes d’ordonnancement séquentiel des activités lors d’un cycle : le mode synchrone et le mode asynchrone [Harrouet, 2000]. Synchrone Un cycle d’ordonnancement synchrone se déroule de la manière suivante : perception : tous les agents perçoivent Etat de l’environnement de l’instant t décision : les agents décident `a partir des perceptions de l’instant t action : les agents font des modifications sur l’environnement perceptibles uniquement `a partir de l’instant t + 1.
Les perceptions d’un agent sont les mêmes, quel que soit son ordre d’éxecution. Il n’y a donc pas de causalité entre les activités durant un cycle.
Asynchrone Lors d’un ordonnancement asynchrone, l’appel des activités conduit a la réalisation successive du cycle historiquement indivisible ≪ perception-décision-action ≫ de chaque agent. Dans ce cas, il existe un lien de causalité entre les différentes activités au sein d’un même cycle de simulation.
La comparaison synchrone/asynchrone est représentée par la figure 2.4.
La méthode asynchrone est plus adaptée dans notre cas pour plusieurs raisons. Premièrement, l’intéret des simulations multi-agents est de pouvoir mettre en oeuvre des mécanismes comme la compétition entre les phénomènes.
Avoir un lien de causalité entre les activités au cours d’un même cycle permet d’assurer la réalisation de ces mécanismes.
Ensuite, l’asynchronisme permet de s’affranchir des problèmes des accès concurrents aux ressources telles que l’environnement.
L’utilisation de solutions classiques comme les sémaphores, nécessaires dans le cas synchrone, risquerait de limiter l’autonomie tant désirée des agents.
Néanmoins, la causalité induite par l’asynchronisme peut amener une activité a être favorisée par rapport `a une autre si la séquence de leur appel est invariable, ce qui risque d’introduire un biais dans la simulation. Une solution acceptable est de brasser les activités a chaque cycle. Pour être efficace, ce brassage doit assurer un tirage aléatoire équiprobable pour chaque activité. Bien entendu, il s’agit d’un tirage sans remise puisque les activités ne doivent être appelées qu’une et une seule fois par cycle. Ce type d’ordonnancement est qualifie de ≪ chaotique ≫. Une composante stochastique est donc introduite dans la simulation. De cette manière, elle n’est plus déterministe.
Plusieurs précautions doivent cependant être prises. Le biais éventuel ne s’annule qu’`a partir d’un grand nombre de cycles. En effet, au premier cycle le choix d’une activité plutôt qu’une autre n’est pas du tout justifie et n’a même aucun sens. De plus, pour permettre a la simulation de se réaliser en temps réel, il faut s’assurer que la somme des temps d’exécution des activités est inférieure au pas de temps entre chaque cycle. Il faut donc trouver un compromis entre précision et puissance de calcul.
Simulations multi-phénomènes et multi-échelles
Certains phénomènes échappent a notre compréhension et doivent être modélisés de fa¸con descriptive conformément `a notre perception. Ils sont parfois si complexes qu’il est impossible de tenir compte de l’ensemble de leurs entités. D’autres sont bien connus et précisément modélises. On a alors `a faire face `a plusieurs granularité de modèles (microscopique, mésoscopique, macroscopique). L’objectif est de pouvoir coupler les modèles dans une simulation multi-echelles [Beal et al., 2008].
Notre cadre applicatif est la cinétique biochimique qui est, comme beaucoup de phénomènes physiques, classiquement modélisée par un système d’EDO3. Celui-ci ne peut cependant être que tr`es rarement résolu analytiquement dans le contexte. La simulation consiste alors `a adopter une méthode numérique pour approximer la solution exacte.
Raideur d’un système d’équations différentielles
Lors de la résolution numérique d’un système d’EDO, la valeur du pas intégration hn est dictée a la fois par la précision numérique souhaitée mais aussi par la stabilité. On dira que le système est raide si la stabilité de la méthode numérique employée induit une contrainte sur le pas de temps plus forte que l’exigence de précision. La raideur apparaît classiquement dans les problèmes o`u le système modélisé implique des ´échelles de temps multiples. Par exemple en cinétique biochimique, la raideur est fréquente dans les problèmes o`u les réactions ont des vitesses ayant des ordres de grandeur différents. Il faudra alors systématiquement adopter une méthode implicite.
Intégration et systèmes multi-agents
Avec une simulation par système multi-agent, le problème global est décomposé en sous systèmes. Les agents résolvent chacun une partie du calcul, `a des vitesses que nous souhaiterions adaptables et heterogenes, pour simuler des phénomènes multi-echelles temporelles. Ces propriétés nous sont assurées par l’asynchronisme présente précédemment.
Avec cette méthode, les agents sont localement itérés puis leurs résultats sont superposes. Cependant, l’approche asynchrone a des limites, notamment dans le cadre de simulations numériques complexes pour lesquelles des schémas de calcul implicites sont indispensable [B´eal et al., 2008]. En effet, la résolution du système implicite introduit par le calcul de yn+1 `a partir de yn par un agent suppose que chaque autre agent a déjà réalise sa partie du calcul global. C’est pourquoi, pour nos travaux, nous nous limiterons aux systèmes additifs qui ont la propriété de pouvoir se résoudre dans un ordre indifférent. Par exemple, pour un système `a deux agents (représentés par les fonctions f1 et f2) résolvant le schéma d’Euler explicite suivant.
Typiquement, chaque pas de temps t ne sera pas une avancée globale pour le système mais deux avancées locales pour les deux sous-systèmes constitues l’un par les variables évoluant lentement, l’autre par les variables évoluant rapidement. Ainsi le pas de temps t sera choisi grand : on intégrera la partie raide du système en un seul pas et l’autre partie pourra être intégrée avec un schéma explicite en divisant le pas t en plusieurs δt [Le Bris, 2005].
L’analyse montre également qu’il est préférable d’intégrer d’abord l’opérateur lent puis l’opérateur rapide de fa¸con `a avoir une meilleure borne sur l’erreur [Le Bris, 2005]. Par ailleurs, la division du problème induit une erreur de décomposition que l’on pourra réduire en décomposant les pas de temps des sous-systèmes. On remarque que cette méthode se rapproche de la simulation par multi-agents par le découpage du problème global en sous-problèmes. La différence se trouve dans le fait qu’ici les calculs se font de manière synchrone. Il pourrait s’agir d’une piste pour le problème entre l’asynchronisme et les schémas implicites expo ´e dans la section précédente.
Parallélisation
Principes
Un ordinateur mono-processeur ne peut exécuter les instructions que l’une après l’autre, passant éventuellement d’un processus `a un autre via des interruptions en simulant le multitâche. Aujourd’hui, les machines multi-processeurs / multi-coeurs permettent d’effectuer des calculs en parallèle. Un des enjeux majeurs de l’informatique moderne est de réussir a tirer profit des récentes architectures parallèles. Pour ce faire, il faut que les applications soient écrites de fa¸con a ce qu’elles soient divisées en plusieurs tˆaches qui puissent être exécutées relativement indépendamment les unes des autres. Le programme doit donc être écrit suivant le paradigme de la programmation concurrente, une méthode de programmation utilisant des mécanismes formalises [Culler et al., 1998], fournis par exemple par les bibliothèques libres POSIX Threads et OpenMP. Le système d’exploitation doit ensuite repartir ces tˆaches sur les différentes unit´es de calcul `a sa disposition.
Mécanismes de synchronisation
La division d’un programme en taches accéléré le traitement dans la plupart des situations même si certaines tˆaches doivent attendre la résolution d’une autre, concurrente sur une ressource par exemple, pour continuer a s’effectuer. Si l’on prend l’exemple d’un programme compos´e de deux tˆaches qui doivent imprimer deux documents différents, il faut empêcher au système d’exploitation de passer d’une tache a l’autre sous peine d’obtenir un patchwork. Pour résoudre ce genre de problème, on doit utiliser un verrou, ou sémaphore, d’exclusion mutuelle afin de bloquer tous les processus tentant d’accéder `a une donnée critique, puis de libérer la ressource pour les processus en attente. Les opérations entre le blocage et la libération du sémaphore sont exécutées de fa¸con atomique. La figure 2.6 illustre ce mécanisme.
Cependant, ce genre de mécanisme doit être utilise avec beaucoup de précaution. Par exemple, si deux tˆaches doivent chacune lire et écrire dans deux variables et qu’elles y accèdent en même temps, cela doit être fait avec précaution. En effet, la première tˆache verrouille la première variable pendant que la seconde tache verrouille la seconde, les deux tˆaches seront mises en sommeil. Il s’agit l`a d’un cas d’interblocage (figure 2.7).
Modèles pharmacocinétiques
Les divers aspects du devenir du principe actif peuvent être décrits a l’aides d’équations matematiques [Jacomet, 1989]. Celles-ci constituent le modèle pharmacocinétique. Ce modèle permet l’analyse de données de pharmacocinétique ou la prédiction de propriétés pharmacocinétiques. Deux types de modèles sont principalement utilises aujourd’hui pour l’élaboration de médicaments.
Modèles compartimentaux
Dans les modèles pharmacocinétiques compartimentaux, l’organisme est modélise par un ensemble de compartiments qui ne sont pas nécessairement identifies `a un organe précis, mais `a des groupes d’organes et de tissus présentant les mêmes propriétés telles que le débit sanguin ou les affinités biochimiques [Leblanc et al., 1990]. Il s’agit d’une représentation très simplifiée de la complexité de du corps humain, mais elle facilite l’écriture des EDO décrivant les transferts du principe actif entre les compartiments. Elle permet également d’identifier les constantes des vitesses d’absorption, de distribution et d’élimination du médicament.
Modèles physiologiques
Le principal inconvénient du modèle pharmacocinétique compartimental est que les compartiments ne référent pas `a des entités anatomiques et physiologiques précises. En effet, il peut être intéressant de faire intervenir les données comme la taille de l’organe, son débit sanguin, la perméabilité des membranes, etc., dans les équations plutôt que de simplement grouper les tissus ayant des propriétés semblables. C’est ce que proposent les modèles physiologiques (figure 2.8), ou PBPK4 [Thomas et al., 1996], qui sont plus proches de la réalité anatomique, et qui permettent de calculer des concentrations vraisemblables des espèces chimiques dans les organes [Bonvallot and Dor, 2002]. S’il ne permettent pas `a eux seuls de valider efficacité et la non nocivité d’un médicament, ils peuvent néanmoins faciliter l’extrapolation des données expérimentales animales chez l’homme et favorisent l’identification des variables physio-pathologiques pouvant modifier la cinétique de celui-ci.
Experimentations
in vivo, in vitro, in silico, in virtuo
Etude des systèmes biologiques complexes est un véritable défi scientifique, qui passe inéluctablement par expérimentation [Bernard, 1865]. Le premier type expérimentation des systèmes biologiques est historiquement expérimentation in vivo qui utilise un modèle vivant, e.g. animal ou humain, pour tester différentes hypothèses.
Les expériences in vitro ont ensuite pris part `a cette quˆété de la compréhension des systèmes biologiques complexes, principalement par le biais de modèles en ´éprouvettes ou en tubes `a essai.
Depuis quelques années, la biologie connait une révolution numérique [Roux, 2009]. En effet, des progrès technologiques ont résulté une explosion de données que seule l’informatique est `a meme de traiter. La notion de calcul in silico [Sieburg, 1990] a alors ´et´e introduite. Celle-ci entreprend l’´élaboration a priori d’un modèle mathématique, qui est ensuite simule numériquement sur ordinateurs, pour aboutir `a l’extrapolation a posteriori des différents résultats. Dans le cas de la pharmacocinétique, les équations différentielles de transfert entre compartiments sont entrées dans l’ordinateur qui résout numériquement le système. Par exemple, le logiciel GastroPlus de Simulation Plus rend ce type de service en permettant de suivre Evolution de la concentration du médicament dans les différents compartiments (figure 2.9).
Cependant, cette méthode prive l’expert de manipuler le modèle. Plus récemment, la possibilité d’interagir avec un programme en cours d’éxecution a ouvert la voie `a une véritable expérimentation in virtuo des modèles numériques. Il est désormais possible de perturber le modèle en cours de simulation, de modifier dynamiquement les conditions aux limites, de supprimer ou d’ajouter des éléments. Ce qui conféré aux modèles numériques un statut de maquette virtuelle, infiniment plus malléable que les modèles in silico. Ces avantages sont d’autant plus évidents pour les systèmes biologiques pour lesquelles des notions telles que Ethique doivent être prises en compte. Notre objectif est de fournir au biologiste la possibilité de manipuler `a loisir son modèle pharmacocinétique dans un laboratoire virtuel, qui représenterait un support de réflexion et Echange inter-disciplinaire pour les experts.
Bilan
Notre ambition est de proposer un modèle générique pour les simulations de systèmes complexes multi- échelles in virtuo. Ainsi, ce chapitre a pourvu un état de l’art des méthodes informatiques utilisées pour ces simulations.
Tout d’abord, nous avons constat´e que les systèmes multi-agents semblent particulièrement adaptes a Etude des systèmes complexes. En effet, afin de simuler un système complexe, les agents peuvent personnifier ses entites, mais aussi ses phénomènes et interactions en introduisant le paradigme SMI. Le meta-modele ReISCOP sera la base de nos travaux. De plus, l’adoption d’un ordonnancement asynchrone chaotique des activités nous donne la possibilité d’ajuster les pas de temps de chacune d’entre elles ainsi qu’un lien de causalité entre les phénomènes.
Ensuite, une comparaison des méthodes numériques pour la simulation multi-phénomènes nous a montre que l’utilisation de schémas implicites est plus indiquée car elle permet d’augmenter le pas de résolution. La parallélisation est aujourd’hui une condition sine qua non pour réaliser des simulations performantes, pour peu que l’on puisse diviser les programmes en tˆaches indépendantes. Enfin, nous avons choisi comme cadre applicatif la pharmacocinétique, car la cietique biochimique et les systèmes complexes tels que les organismes vivants sont source de phénomènes multi-echelles. Ajoutons qu’aujourd’hui, aucune application ne propose au biologiste de manipuler son modèle en cours de simulation. Nous allons maintenant détailler notre proposition dans un troisième chapitre.
Proposition d’un modèle générique pour les simulations multi-échelles
De nombreux problèmes relevant des systèmes complexes (e.g. physique, mécanique, biochimie), font apparaître plusieurs échelles d’espace ou de temps. Elles peuvent également être des échelles d’observation ou de description des divers phénomènes étudies. Le traitement numérique efficace de tels problèmes nécessite une approche spécifique. Une des difficultés majeures, outre la puissance de calcul nécessaire pour la résolution numérique, est de parvenir `a coupler les différentes échelles de simulation afin d’obtenir un état global du système. C’est pourquoi nous proposons ici un modèle générique pour la simulation in virtuo des systèmes multi-échelles. Le contexte de l’équipe in virtuo et plus généralement du CERV nous incite a utiliser une approche multiagents et plus particulièrement le paradigme Multi-interactions introduit par le modèle R´eISCOP [Desmeulles, 2006]. A partir de cela, nous apportons quelques modifications au modèle d’origine et nous retendons pour le support de multiples ´échelles. Ce chapitre est alors construit de la maniéré suivante. Tout d’abord, nous détaillons notre conception d’une échelle isolée. Les entités, interactions et phénomènes qui la composent sont expos´es dans cette première partie. Nous introduisons ´également un nouveau type d’agent, l’agent intégrateur, qui doit pallier les problèmes de stabilité induits par l’asynchronisme. Ensuite, nous présentons les méthodes d’ordonnancements des éléments actifs au sein d’une échelle. Enfin, une deuxième partie traitera de la possibilité de simuler plusieurs échelles parallèlement et de leurs mécanismes de couplage.
Modélisation d’une échelle
Une hi´hiérarchie d’entités en interaction
Comme nous l’avons vu précédemment, un système complexe est compose d’une multitude d’entites (figure 3.1). Dans une approche agent classique, elles sont chacune représentées par un agent autonome évoluant dans un environnement, grˆace au cycle ≪ perception – décision – action ≫. On qualifie ce type de modélisation d’≪ individucentree ≫. La vitesse d’éxecution d’une simulation est généralement fonction du nombre de ces entités (tout dépend de leurs calculs), ce qui pose problème pour les systèmes que nous étudions. Le paradigme multi-interactions permet de réduire le nombre d’entités actives en réifiant, c’est-`a-dire en ≪ objectifiant ≫, les interactions du système et en les dotant d’un comportement. On constate au moins deux avantages `a cette méthode. Tout d’abord, cela permet au modélisateur de se placer `a un niveau de modélisation plus macroscopique tout en conservant l’intéret d’une architecture individu-centrée et orientée agent. De plus, l’état de l’art a montre que les interactions entre enties sont le plus souvent décrites comme un système d’équations différentielles. Le modélisateur est donc plus a même de décrire le comportement de l’interaction plutôt que ceux des entités. Ensuite, le nombre d’objets actifs dans la simulation diminue. Par exemple, au lieu de considérer deux molécules qui font chacune l’action de réagir avec l’autre, on introduit un agent réaction qui se charge de calculer l’interaction une seule fois et de l’appliquer sur les protagonistes. L’agent n’est donc plus l’entite mais l’interaction.
Cependant, comme nous le verrons plus tard, l’autonomie d’éxecution de l’agent interaction peut compromettre la stabilité du système dans le cadre d’une simulation asynchrone et de l’utilisation de schémas intégration implicites. C’est pourquoi, nous nous éloignons du modèle de base en le privant sa capacité a s’activer seul, tout en gardant inchangé le concept de réification. Ainsi les primitives de perception, de décision et d’action de l’agent interaction sont conservées. Le nouveau mécanisme d’activation sera présente par la suite.
Nous apportons également une autre modification a R´eISCOP en fusionnant les notions de Constituant et d’Organisation en une seule classe Entity. On peut en effet considérer qu’un organe est constitu´e de cellules mais aussi qu’il est un constituant du corps. Les entités sont ensuite agencées en hiérarchie. Ainsi, comme le montre la figure 3.2, une entité peut contenir des entités, qui peuvent elles-mêmes contenir des entités, etc. L’ajout de cette hiérarchie entre les entités parait de plus indispensable dans le cas de Etude de plusieurs échelles spatiales. Nous nous sommes cependant pose la question du sort des sous-entités lors de la disparition de leur super entité. L`a o`u ReISCOP suggère que la suppression de l’Organisation n’implique pas celle de ses Constituants, nous considérons qu’il appartient au modélisateur de décider de leur avenir. En effet, si aucune interaction n’est prévue pour gererces éléments, ils n’ont plus de raison dˆêtre dans le système.
L’agent intégrateur
Comme nous l’avons vu dans l’´état de l’art, de nombreux phénomènes sont décrits a l’aide de systèmes d’équations différentielles. Ces systèmes sont en général difficilement résolubles analytiquement. On a alors besoin de méthodes numériques pour les résoudre pas a pas et ainsi faire ´évoluer Etat du monde au cours de la simulation.
Cependant, l’utilisation de systèmes ≪ interaction-centres ≫ nous contraint a adopter des schémas intégration explicites.
En effet, chaque interaction intègre indépendamment sa partie du calcul global sur le système. Or l’utilisation d’un schéma implicite implique que l’ensemble des autres interactions aient déjà effectue cette même action, puisque l’on considéré la dérivée au point d’arrivée. Les interactions étant indépendantes, elles n’ont pas la capacité de savoir si c’est effectivement le cas. De plus, cela ne serait pas souhaitable car on perdrait ainsi l’autonomie de conception du modèle. C’est pourquoi nous avons retiré l’autonomie d’éxecution des interactions. Notre idée est d’extraire la partie intégration de chaque interaction et de la r´réifier en un objet actif unique au sein de l’´échelle. Il sera chargé d’ordonnancer les calculs et de faire évoluer l’´état du système. Dans notre modèle, ce rôle est rempli par l’agent intégrateur. En connaissant toutes les interactions en présence, il contrôle la justesse des calculs ainsi que leur application sur les entités. Nous pouvons par exemple imposer une borne sur l’erreur commise par le calcul de l’interaction. L’ordonnancement des calculs et leur application correspondent au cycle ≪ perception – décision – action ≫ de l’agent intégrateur. On peut distinguer deux approches différentes pour leur mise en place.
|
Table des matières
1 Introduction
2 Etat de l’art
2.1 Systèmes et simulation
2.1.1 Systèmes complexes
2.1.2 Systèmes multi-agents
2.1.3 ReISCOP : le paradigme multi-interactions
2.1.4 Ordonnancements
2.2 Simulations multi-phenomenes et multi-echelles
2.2.1 Méthodes numériques
2.2.2 Méthodes de séparation d’opérateurs
2.2.3 Parallélisation
2.3 Pharmacocinétique
2.3.1 Modèles pharmacocinétiques
2.3.2 Expérimentations
2.4 Bilan
3 Proposition d’un modèle générique pour les simulations multi-echelles
3.1 Modélisation d’une échelle
3.1.1 Une hiérarchie d’entités en interaction
3.1.2 Les phénomènes
3.1.3 L’agent intégrateur
3.1.4 Méthodes de résolution de systèmes d’´équations différentielles
3.1.5 Ordonnanceurs
3.2 Vers un modèle multi-echelles
3.2.1 Le système central
3.2.2 Cohérence des données
3.2.3 Des interactions entre les echelles
3.3 Bilan
4 Application a la pharmacocinétique virtuelle
4.1 Contexte
4.2 Hémostase
4.2.1 Introduction
4.2.2 Troubles de l’hémostase
4.2.3 Variabilité individuelle de l’effet dose-réponse
4.2.4 Vers une simulation in virtuo de la pharmacocinétique des AVK
4.3 Dérivation du modèle pour la biologie
4.3.1 L’entité chimique
4.3.2 Réactions
4.3.3 Diffusion
4.3.4 Synthèse et élimination
4.3.5 Bilan
4.4 Distribution et effets des AVK
4.4.1 Modélisation
4.4.2 Résultats
4.5 Temps de Quick et INR invirtuo
4.5.1 Principe
4.5.2 Modèle numérique
4.5.3 Résultats
4.6 D’autres échelles de simulation
4.7 Bilan
5 Conclusion et perspectives
![]() Télécharger le rapport complet
Télécharger le rapport complet