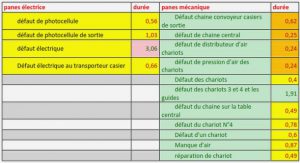
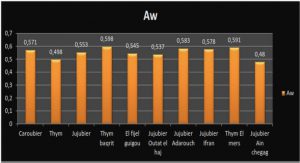
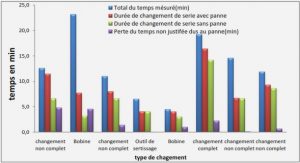
Télécharger le fichier pdf d’un mémoire de fin d’études
La supervision et le diagnostic
La supervision est définie comme étant la surveillance, le diagnostic et la décision, c.-à-d, elle consiste à gérer et à surveiller l’exécution d’une opération ou d’un travail accompli par l’homme ou par une machine, puis proposer des actions correctives si besoin est.
La supervision continue des systèmes industriels est nécessaire pour assurer des conditions d’opération pour lesquelles les algorithmes de commande sont efficaces.
Lorsque la fonction de surveillance est réalisée par un opérateur humain, viennent s’ajouter au problème du choix des méthodes et architecture de cette fonction, des concepts liés à l’ergonomie des systèmes développés. Il est apparu entre autre, que les défauts les plus difficiles à détecter sont les défauts qui s’installent lentement, sous forme de dérives, car on peut mettre un certain temps à voir leurs effets apparaitre clairement.
Les méthodes avancées de diagnostic de défauts sont nécessaires, pour répondre aux exigences comme l’anticipation de la détection de défauts avec variations brutales du comportement, le diagnostic de fautes d’actionneur, de comportement du système et du capteur, la détection de défauts dans les boucles fermées et la supervision des systèmes lors d’états transitoires. L’objectif de l’anticipation de la détection de défauts et du diagnostic est d’avoir assez de temps pour traiter des actions, comme la reconfiguration du système ou la maintenance.
Selon [NOU 05], la supervision nécessite la mise en œuvre de nombreuses tâches décrites par la Figure 1.2.
Ces différentes tâches sont détaillées dans ce qui suit:
L’extraction des informations nécessaires à la mise en forme des caractéristiques associées aux fonctionnements normaux et anormaux, à partir des moyens de mesures appropriées ou d’observations réalisées hors des rondes par les personnels de surveillance.
La caractérisation des défauts est l’élaboration des caractéristiques et signatures associées à des symptômes révélateurs de défaillances et de dégradations en vue de la détection d’un dysfonctionnement.
La détection de défauts permet de déterminer si le système physique fonctionne normalement et a pour objectif de signaler la présence d’un défaut en comparant le comportement courant du système avec celui donné pour référence.
L’opération de localisation qui suit l’étape de détection a pour objet la localisation d’un défaut détecté survenant sur les actionneurs, les capteurs d’instrumentation, la commande ou le système commandé en indiquant quel organe ou composant est affecté par celui-ci.
La tâche d’identification a pour but de caractériser le défaut en durée et en amplitude afin de le classifier par types et degrés de sévérité. Ainsi, il peut servir à assurer le suivi de son évolution, ce qui est fort utile dans le cas d’un changement de comportement lent dû au vieillissement et à l’usure. De plus, cette tâche peut comprendre une procédure visant à déterminer la cause du défaut, c’est-à-dire son origine.
Ces trois dernières tâches constituent le corps d’une procédure de diagnostic.
Lorsqu’une anomalie est détectée, le module de diagnostic doit donc :
– vérifier que celle-ci est bien un défaut,
– puis, localiser le défaut pour déterminer le composant incriminé,
– enfin, identifier le défaut, c’est-à-dire déterminer ses caractéristiques.
La prise de décision en fonction des conséquences futures des défaillances et des dégradations. Cette prise de décision peut conduire à un arrêt de l’installation si ces conséquences sont importantes.
Méthodes à base de modèles
Ces méthodes reposent sur une connaissance physique profonde du système à diagnostiquer. La méthode de diagnostic s’appuie sur la comparaison du comportement réel observé sur le système physique avec le comportement prédit à l’aide de modèles de son comportement nominal. La détection d’incohérences permet de conclure sur l’occurrence de faute dans le système. Un modèle de dysfonctionnement (modèle de faute) permet de localiser les fautes et éventuellement de les identifier.
Deux principales approches peuvent se distinguer dans les méthodes de diagnostic à base de modèles: les méthodes quantitatives FDI (Fault Detection and Isolation) issues de la communauté automatique et les méthodes qualitatives issues des communautés de l’intelligence artificielle (IA) et des systèmes à événements discrets (SED).
Méthodes à base de modèles qualitatifs
Les modèles qualitatifs permettent d’abstraire le comportement du procédé avec un certain degré d’abstraction à travers des modèles non plus mathématiques mais des modèles de type symbolique. Contrairement aux modèles de type numérique, les modèles qualitatifs ne représentent pas la physique du système, mais ils le décrivent en terme de mode de fonctionnement [DER 09]. Divers modèles de représentation qualitative des systèmes continus, discrets et hybrides ont été utilisés dans le cadre de diagnostic. Parmi les méthodes les plus populaires, citons les graphes causaux pour les systèmes continus, les automates d’états finis et les réseaux de Petri pour les systèmes discrets et les automates hybrides [DER 09], les bond graphs et réseaux de Petri hybrides pour les systèmes hybrides [MOK 07].
Une limitation importante de ces méthodes réside dans la génération d’un grand nombre d’hypothèses pouvant conduire à une résolution erronée du problème ou à une solution très incertaine.
Méthodes à base de modèles quantitatifs
Le principe de diagnostic à base de modèles quantitatifs consiste à comparer le comportement réel du système tel qu’il peut être observé par l’intermédiaire de capteurs et son comportement attendu tel qu’il peut être prédit grâce aux modèles de bon fonctionnement. Toute contradiction entre les observations et les prédictions déduites des modèles, autrement résidu où indicateur de défaut, permet de révéler la présence d’un ou plusieurs défauts, comme illustré sur la figure 1.4. Les techniques de génération de résidus seront différentes. Trois approches sont particulièrement utilisées pour la génération des résidus [COC 04]:
– L’approche d’estimation paramétrique: qui consiste à identifier en ligne les divers paramètres du système et à comparer ses estimations aux valeurs nominales des paramètres. L’erreur d’estimation est utilisée comme résidu. Le lecteur intéressé par cette approche pourra consulter par exemple le travail de [BAC 02].
– L’approche de l’espace de parité: son principe est de transformer, réécrire les équations du modèle de manière à obtenir des relations particulières appelées RRA: Relations de Redondance Analytique. Ces relations ont pour propriété de ne lier que des grandeurs connues, disponibles en ligne. Les résidus sont obtenus en substituant dans ces RRA les variables connues par leurs valeurs réelles, prélevées sur le système en fonctionnement. L’obtention hors-ligne des RRA est un problème général d’élimination de variables dans un système d’équations algébro-différentielles. Lorsque le modèle est linéaire, l’élimination peut se faire par projection dans un sous espace appelé espace de parité.
– L’approche à base d’observateurs ou de filtres: son principe général est de concevoir un système dynamique permettant de donner une image, ou estimation, de certaines variables, ou combinaisons de variables, nécessaires au bouclage. Ces outils ont été adaptés à des fins de diagnostic et les travaux utilisant ces approches sont nombreux, on peut citer [BOU 01] [NAI 00]. L’écart entre les fonctions de sorties estimées et les mêmes fonctions des sorties mesurées est utilisé comme résidu.
Méthodes sans modèle
Dans certaines applications industrielles, il est difficile, voire impossible, d’obtenir le modèle du système. Cette difficulté est justifiée par la complexité du système. En effet, seules les méthodes de diagnostic sans modèles sont opérationnelles pour ce type d’applications industrielles. Ces méthodes de diagnostic se basent sur des informations issues d’une expérience préalable ou sur des règles heuristiques.
Dans cette partie, nous allons présenter quelques unes de ces techniques ainsi que leur application dans le domaine du diagnostic des systèmes industriels.
Méthodes Qualitatives
• Systèmes expert
Un système expert (SE) est un logiciel destiné à assister l’homme en incorporant la connaissance et l’expérience des spécialistes [BRU 90]. En d’autres termes le but de reproduire le raisonnement qui conduit un expert humain à prendre une décision sur l’état du système à partir d’observations de celui-ci, données sous forme symbolique.
L’architecture générale d’un système expert se comporte principalement de trois éléments (figure 1.5): une base de connaissance, un moteur d’inférence et des interfaces utilisateurs.
– La base de connaissance se compose généralement de deux parties: la base de faits et la base de règles. La base de faits (BF) regroupe toutes les observations faites sur le système à diagnostiquer. La base de règles (BR) contient les connaissances opératoires représentant le « savoir-faire » sur le domaine étudié.
– Moteur d’inférence: C’est le programme qui combine les faits, déclenche les règles
applicables et génère de nouveaux faits. Le moteur répète le cycle suivant: sélection des règles, filtrage des règles, résolution des conflits et enfin exécution.
– Interfaces utilisateurs: Les interfaces utilisateurs permettent aux opérateurs de consulter le système expert. Ils peuvent ainsi vérifier et éventuellement mettre à jour leurs connaissances.
Structuration de l’espace de représentation
La structuration de l’espace de représentation consiste à chercher des régions, de l’espace de représentation, correspondant à chaque mode de fonctionnement. Cette étape fait appel à des techniques de classification, à partir de l’ensemble d’apprentissage. La classification peut être de deux natures, exclusive ou non. Le premier cas, lorsque toute observation appartient à une seule classe. En effet, chaque observation pourrait être munie d’un vecteur de fonctions d’appartenance caractérisant le degré d’appartenance de celle-ci à chacune des classes. Le second cas, lorsqu’une même observation peut appartenir à plusieurs classes. L’algorithme fournit alors une valeur numérique de l’appartenance de l’observation à chaque classe.
Lorsqu’on connaît la classe d’origine de chaque observation, l’espace de décision est parfaitement connu et l’apprentissage peut être effectué en mode supervisé, une telle approche permettrait d’établir directement une relation entre l’espace d’entrée et celui de sortie (c’est à dire entre les observations et les différentes classes ou modes de fonctionnement). Parmi ces méthodes [RAG 03] on peut citer les méthodes probabilistes, les K plus proches voisins, les réseaux de neurones à bas radiale, réseaux de neurones de type perceptron, les systèmes d’inférence floue et les machines a vecteurs supports.
Si au contraire on ne dispose d’aucune information sur la structuration de l’ensemble d’apprentissage en classes (c’est-à-dire on ne connaît pas les modes réels de fonctionnement des observations), l’apprentissage est dit non supervisé. Les méthodes de classification non supervisée, autrement appelées méthodes de coalescence, sont généralement intégrées dans des architectures plus complexes.
Exploitation du système de diagnostic
Une fois la règle de décision déterminée, l’étape suivante consiste à reconnaître à quel mode de fonctionnement correspond une nouvelle observation effectuée à un instant donné sur le système. Un problème peut survenir si cette observation ne peut être affectée à une classe (rejet en distance ou en ambiguïté). Dans ce cas il convient à interpréter ce rejet en termes de causes de ce changement de fonctionnement. Cela ne peut être que par un expert.
La méthode de diagnostic doit être adaptative, elle doit permettre de rechercher une nouvelle structure en classe pour les points rejetés, dès lors que leur nombre devient significatif. Un nouvel apprentissage est relancé afin de prendre en compte cette classe supplémentaire. La règle de décision est aussi à adapter.
La figure 2.6 représente une architecture d’un système de diagnostic adaptatif. A chaque présentation d’une nouvelle observation , le module de décision affecte l’observation présentée, à l’une des classes connues a priori ou à la classe de rejet de distance si l’observation est éloignée de toutes les classes, ou à la classe de rejet d’ambiguïté si elle appartient au moins à deux classes de l’ensemble d’apprentissage. Lorsque la nouvelle observation est affectée à la classe avec ∈ {1,• • • , }, les caractéristiques (paramètres du modèle) de celle-ci sont mises à jour. La mise à jour en continu des paramètres des modèles permet de suivre en temps réel l’évolution des classes correspondant aux modes de fonctionnement. Les observations affectées à la classe seront utilisées pour mettre en évidence l’apparition de nouveaux modes de fonctionnement du système. Le diagnostic adaptatif permet de déterminer à chaque instant l’état dans lequel le système se trouve et éventuellement de décider s’il est nécessaire de créer une nouvelle classe correspondant à un nouveau mode de fonctionnement. Lorsque des nouveaux sont détectés, l’expert ou l’utilisateur les labellise en termes de modes de fonctionnement des nouvelles classes identifiées. La confirmation et la labellisation se feront en fonction du nombre minimal d’observations affectées à la classe par le module de décision et en fonction de la similarité des observations contenues dans [TRA 10].
Classification floue non supervisée
Le problème central en reconnaissance des formes floue réside dans l’apprentissage des fonctions d’appartenance à partir des données. Lorsque celles-ci se composent de vecteurs =1 non étiquetés (apprentissage non supervisé). Ce problème rejoint celui de la classification automatique en analyse des données, et peut être formalisé comme la recherche d’une partition floue des observations, généralisant la notion classique de partition d’un ensemble de points.
Une partition de l’ensemble d’apprentissage en classes peut être décrite par une matrice à lignes et colonnes, de terme général , , et telle que , = 1 si appartient à la classe , et , = 0 sinon. Tout vecteur appartient à une seule classe, ce qui implique:, = 1 ∀ (2.41)
En outre, on peut supposer qu’aucune classe n’est vide, ce qui implique que: , > 0 ∀ (2.42)
Une matrice de partition floue se définit comme une matrice de terme général , ∈ 0,1 vérifiant les équations (2.41) et (2.42) précédentes. La quantité , s’interprète alors comme degré d’appartenance (prenant n’importe quelle valeur réelle entre 0 et 1) de l’objet à la classe .
Approche de C moyennes possibilistes modifiée
Selon Khodja, le rapprochement des centres observé avec l’algorithme PCM n’est pas uniquement dû à une mauvaise initialisation de la partition. En effet, lorsque les deux centres sont confondus, la méthode a été probablement mal initialisée. Cependant, ceci n’explique pas la décroissance très rapide de la distance inter-centres calculée à l’aide de l’approche PCM. Khodja [KHO 07] a opté pour la limitation de la contribution des points les plus éloignés d’un centre donné dans le calcul des coordonnées de ce centre, sachant que la réduction des valeurs de l’indice du flou m, proposée par Krishnapuram et Keller pour obvier au problème de confusion des centres s’est avérée insuffisante. Le nouvel algorithme proposé par Khodja repose sur le remplacement de la formule des degrés d’appartenance (2.56) par la Formule suivante: 2 −1 = 1 + − −1 ∀ , (2.58)
L’exposant au dénominateur est augmenté, ce qui assure la rapidité dans la décroissance recherchée. Cette approche, appelé MPCM (Modified Possibilistic C-Means), présente l’avantage de sauvegarder les apports espérés de l’approche possibiliste, tout en éliminant l’inconvénient fâcheux de confusion des centres.
Le critère proposé par Khodja est le suivant: , = − 2 + 1 − (2.59)
Les problèmes en classification
Validation du nombre des classes
Les algorithmes de classification floue précédents nécessitent la connaissance à priori du nombre des classes, ce qui n’est pas toujours possible. Différentes partitions sont ainsi obtenues pour différentes valeurs de . On est alors obligé de définir un critère, ou une fonction de validité, mesurant la performance de la classification pour choisir le nombre optimal de classe . C’est ce qu’on appellera indice de validité des classes (cluster validity index).
Le processus pour le calcul de l’indice de validation des classes est résumé par les étapes suivantes:
1) Appliquer l’algorithme de classification pour différents valeurs de avec est fixé par l’utilisateur).
2) Calculer l’indice de validité pour chaque partition obtenue à l’étape précédente.
3) Choisir le nombre optimal ∗ de classes.
Nous présentons au tableau suivant quelques critères de validation les plus utilisés ainsi que leurs règles d’utilisation. Les deux premiers critères sont conçus spécialement pour l’algorithme de FCM, les autres critères peuvent être appliqués à n’importe quel algorithme de coalescence floue.
Qualité de l’eau à la sortie de la station :
La station de traitement est conçue pour pouvoir assurer une alimentation fiable et continue en eau potable, exempte d’organismes pathogènes. Dans les conditions de qualité de l’eau contractuelles et d’une exploitation normale, la qualité finale de l’eau après traitement doit être conforme aux normes suivantes 100 % du temps [DEG 08].
• Turbidité (avant injection de chaux) inférieure à 1,0 NTU
• Goût et odeur acceptables pour le consommateur
• Couleur inférieure à 5° Hazen
• Aluminium (Al) inférieur à 0,2 mg/l
• Fer (Fe) inférieur à 0,3 mg/l
• Manganèse (Mn) inférieur à 0,1 mg/l
• pH 6,5 à 8,5
• E coli ou bactérie thermotolérante néant sur tout échantillon de 100 ml
• Total bactéries coliformes néant sur tout échantillon de 100 ml
En ce qui concerne les autres paramètres individuels, ils seront inférieurs aux valeurs désirables les plus élevées recommandées par les normes les plus récentes de l’OMS pour les eaux de boisson.
Exploitation de la station
Etapes du traitement de l’eau
La station de TAKSEBT est composée de deux chaines de traitement identiques. L’eau traitée au niveau de la station passe par plusieurs ouvrages avant d’arriver au bout de la station (réservoir de stockage). Les différentes étapes de traitement sont:
– La dissipation, le mélange et la répartition;
– La coagulation et floculation;
– La filtration;
– La désinfection et le stockage (réservoir).
Dissipation, mélange et répartition :
L’arrivée d’eau brute à la station de TAKSEBT se fait dans la chambre de dissipation. L’eau surnageant des dessableurs est également retournée dans la chambre de dissipation. Les déversoirs en sortie de la chambre assurent un niveau minimum, donc un volume tampon capable de tranquilliser l’arrivée d’eau brute. Si nécessaire, il est possible de procéder à une préchloration dans l’ouvrage, principalement dans le but de limiter la présence d’organismes (algues, bactéries, plancton) susceptibles de proliférer dans les filières de traitement [DEG 08].
La chambre d’arrivée possède un volume de 430 m3 assurant un temps de rétention de 60 secondes au débit d’eau brute maximal de 616 000 m3/j.
L’injection de chlore, de sulfate d’aluminium, d’acide sulfurique, de permanganate de potassium et de charbon actif en poudre s’effectue dans cette chambre. Le mélange des produits chimiques est réalisé dans les trois déversoirs vers la chambre de mélange.
Un trop-plein est prévu dans la chambre d’arrivée pour dévier le débit excédentaire. Ce trop-plein est calé à l’élévation 165,55 m et la lame d’eau est de 22 cm au débit maximal de 647 000 m3/j. Certaines caractéristiques de l’eau brute (conductivité, pH et turbidité) sont mesurées en permanence.
L’eau brute passe ensuite à travers la chambre de mélange. Cet ouvrage assure un temps de contact suffisant pour assurer le mélange homogène des réactifs.
Les réactifs remplissent les fonctions suivantes :
• Permanganate de potassium : limiter la présence de manganèse et/ou contrôler la charge biologique.
• Charbon actif en poudre : contrôle du goût et des odeurs.
• Sulfate d’alumine : coagulant pour faciliter la clarification dans les décanteurs Pulsatube.
• Acide sulfurique : ajustement du pH pour optimiser la coagulation.
L’ouvrage de répartition permet deux choix d’exploitations :
Une répartition équilibrée du débit vers les décanteurs Pulsatube (2 filières de 4 décanteurs chacune).
Une réparation du débit vers les ouvrages de by-pass des décanteurs (1 canal pour chaque filière). Lorsque les canaux de by-pass sont utilisés, un polymère y est injecté, de manière à assurer une floculation directement sur les filtres.
|
Table des matières
Introduction générale
Chapitre 1: Terminologie et principe du diagnostic des systèmes industriels
1.1. Introduction
1.2. Concepts et terminologie
1.3. La supervision et le diagnostic
1.4. Les différentes méthodes de diagnostic
1.4.1.Méthodes à base de modèles
1.4.1.1. Modèles causaux qualitatifs
1.4.1.2. Méthodes à base de modèles quantitatifs
1.4.2.Méthodes sans modèles
1.4.2.1. Méthodes qualitatives
1.4.2.2. Méthodes quantitatives
1.5. Conclusion
Chapitre 2: Méthodes de reconnaissance des formes floue
2.1. Introduction
2.2. Procédure de diagnostic par reconnaissance des formes
2.2.1. Détermination de l’espace de représentation
2.2.1.1. Réduction de l’espace de représentation
2.2.1.1.1. Extraction de variables
2.2.1.1.2. Sélection de variables
2.2.2. Structuration de l’espace de représentation
2.2.3. Choix d’une méthode de décision
2.2.4. Exploitation du système de diagnostic
2.3. Reconnaissance des formes floue
2.3.1. Approche floue
2.3.2. Méthodes floues de classification supervisée
2.3.3. Classification non supervisée
2.3.3.1. Algorithme FCM
2.3.3.1.2. Avantages et inconvénients
2.3.3.2. Les variantes des C moyennes floues
2.3.3.2.1. Approche de GK
2.3.3.2.2. Approche de C moyennes possibilistes
2.3.3.2.3. Approche de C moyennes possibilistes modifiée
2.3.3.3. Les problèmes en classification
2.3.3.3.1. Validation du nombre des classes
2.3.3.3.2. Méthodes d’initialisation de la partition
2.3.4. Modélisation des modes de fonctionnement
2.3.5. Règle de décision
2.4. Conclusion
Chapitre 3: Application de la méthode à la station de production de l’eau potable de TAKSEBT
3.1. Introduction
3.2. Description de la station
3.2.1. Capacité de la station
3.2.2. Qualité de l’eau à l’entrée de la station
3.2.3. Qualité de l’eau à la sortie de la station
3.2.4. Exploitation de la station
3.2.4.1. Les étapes du traitement de l’eau
3.2.4.1.1 Dissipation, mélange et réparation
3.2.4.1.2. La coagulation & floculation
3.2.4.1.3. La décantation
3.2.4.1.4. La filtration
3.2.4.1.5. Désinfection et stockage de l’eau traitée
3.2.5. Aspects fonctionnels de la station
3.3. Résultats liés au diagnostic de la station
3.3.1. Phase d’apprentissage hors ligne (classification des données)
3.3.2. Phase de reconnaissance en ligne
3.4. Conclusion
Conclusion générale
Références bibliographiques
Télécharger le rapport complet