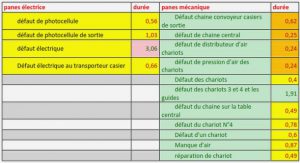
Grilles indépendantes
Afin de mailler avec précision la géométrie du domaine à tous les niveaux, l’utilisation de maillages indépendants s’impose, même si elle nécessite la construction d’opérateurs plus complexes. Dans (Feng et al., 1997), les auteurs développent une méthode multigrille basée sur des maillages non structurés et indépendants pour la résolution de problèmes linéaires et non linéaires de la mécanique du solide. Celle-ci fournit des résultats très encourageants sur diverses applications en 2D et 3D. Par exemple, avec les maillages indépendants présentés sur la figure 1.6, la résolution du problème élastique comportant 81 500 degrés de liberté par la méthode multigrille permet une accélération d’un facteur 5,5 par rapport au solveur itératif par gradient conjugué. (Adams, 2002) met toutefois en évidence les inconvénients des multigrilles basées sur des maillages indépendants :
– Même si les cycles de résolution apparaissent comme très efficaces étant donnée la bonne représentation géométrique des différents niveaux, cette méthode fait face à d’importants coûts de construction. En effet, l’utilisation de maillages indépendants complexifie la construction des opérateurs de transfert, généralement basés sur l’interpolation des noeuds du maillage fin sur les éléments du maillage grossier pour l’opérateur de restriction, puis des noeuds grossiers sur le maillage fin pour l’opérateur de prolongement (figure 1.7). Pour les problèmes non linéaires ou incrémentaux, cet inconvénient est néanmoins atténué puisque ces opérateurs servent à la résolution de nombreux systèmes linéaires.
– Des problèmes de robustesse peuvent également être induits par l’algorithme de déraffinement de maillage. Dans l’exemple utilisé par (Adams, 2002), l’algorithme de Delaunay permettant de générer les niveaux grossiers engendre des maillages trop grossiers qui ne permettent pas la convergence de l’algorithme multigrille. Ce problème met en évidence la nécessité d’un contrôle sur la conservation du volume du domaine ou sur un nombre de nœuds minimal à respecter.
Mailleur topologique MTC
La formulation utilisée dans FORGE R NxT est basée sur une approche lagrangienne, le maillage suivant la déformation de la matière. Cependant, la pièce subissant des grandes déformations lors des procédés de mises en forme, les éléments finissent par être de moins bonne qualité et par ne plus correctement représenter la géométrie du domaine. Une étape de remaillage s’effectue alors, permettant la génération d’un nouveau maillage adapté au domaine déformé et la continuité du calcul. Elle s’appuie sur un processus itératif d’optimisations locales. Afin de présenter l’algorithme du mailleur topologique, nous devons introduire les notions de topologie et de critère de volume minimal.
Stratégie SPMD
Le parallélisme adopté dans le logiciel FORGE R NxT suit une approche SPMD (Single Program Multiple Data) basée sur une partition du maillage. Dans (Karaseva, 2005), l’auteur montre en effet que cette approche se révèle plus efficace que la décomposition de domaine avec une méthode de type FETI, décrite par exemple par Farhat et Roux (Farhat et al.,1994). Le maillage éléments finis du problème discret est donc ici partitionné en plusieurs sousdomaines de dimensions équivalentes. Afin de gagner en efficacité, ce partitionnement est généré de façon à minimiser la taille des interfaces entre les sous domaines ce qui permet de limiter les communications. Le code de calcul s’exécute ensuite sur chaque processeur avec les conditions limites du problème global, tout comme les conditions de contact et de frottement. La surface de contact étant une inconnue du problème, les paramètres de pilotage et la structure des outils sont dupliqués sur chaque processeur et l’analyse de contact se fait localement sur tous les processeurs.
Partitionnement et remaillage
Le partitionnement du maillage constitue une étape importante pour la parallélisation, la performance du calcul dépend de la taille des interfaces entre les sous-domaines et du bon équilibre des charges. Le partitionneur s’appuie sur la topologie du maillage et travaille en deux étapes, décrites succintement ici et en détail par (Marie, 1997) et (Digonnet, 2001) :
– Un algorithme dit « glouton » commence par déterminer Nproc éléments de maillage appelés « germes » aussi distants que possible les uns des autres, avec Nproc le nombre de processeurs du calcul. Chacun de ces germes constituera le centre d’un sous-domaine de la partition, autour duquel la partition sera construite en y ajoutant les éléments adjacents.
– Une amélioration du partitionnement obtenue avec cet algorithme glouton s’effectue par minimisation du nombre de nœuds aux interfaces. Pour cela, à chaque élément on attribue un critère prenant en compte le nombre total d’éléments par processeur et le nombre de communications avec des éléments d’autres processeurs. En résulte une réattribution ou non de l’élément à un autre processeur. Le remaillage parallèle repose sur le principe du remaillage séquentiel vu dans la section précédente 2.3 sous la contrainte du blocage des nœuds des interfaces entre les sous-domaines. L’algorithme est le suivant : Tant que la totalité du domaine n’a pas été remaillée :
– La procédure de maillage séquentiel est effectuée en parallèle sur chaque processeur, sans modifier les interfaces. Elle ne nécessite aucune communication entre les processeurs.
– La procédure de repartitionnement est effectuée, rééquilibrant les tailles des sousdomaines et déplaçant les interfaces afin que celles-ci puissent être traitées lors du prochain remaillage.
Construction parallèle des maillages grossiers
Pour construire les niveaux de calcul grossier, on se base sur la génération de maillages construits par déraffinement à partir du maillage fin. Comme vu dans le chapitre 1, section 1.3, la génération de maillages emboités (Rey, 2007) ne permet pas de traiter des géométries complexes. Nous utilisons donc ici une approche non emboitée. Lors d’un calcul parallèle, le maillage initial, fournissant la géométrie du domaine, est partitionné en plusieurs sous-domaines répartis sur les différents processeurs. La génération des maillages grossiers doit donc se faire également de manière parallèle, en s’inspirant de l’approche décrite dans la section 2.3.1, sur la base des travaux de (Gruau et Coupez, 2005) et de (Coupez et al., 2000). A partir du maillage initial, un maillage plus grossier est généré de manière itérative en suivant les étapes présentée sur la figure 3.1, combinant remaillage local et repartitionnement de maillage. On illustre cette stratégie sur un maillage 2D mais la méthode est naturellement compatible avec un problème 3D. Le choix de la taille de maille du maillage grossier sera discuté dans la section 3.2.2. Sur ce domaine 2D (figure 3.1.1), les partitions du maillage initial subissent tout d’abord un déraffinement parallèle en bloquant les interfaces entre les sous-domaines (figure 3.1.2). Un repartitionnement parallèle du domaine (figure 3.1.3) permet ensuite le déplacement de ces interfaces, de telle sorte qu’elles puissent être remaillées durant l’étape de déraffinement suivante (figure 3.1.4). Ce processus est répété jusqu’à obtenir le déraffinement complet de la géométrie initiale. Le nombre d’opérations à effectuer décroît rapidement avec les itérations de remaillage/repartitionnement. La diminution du nombre d’éléments à traiter permet de générer ces maillages grossiers en un temps raisonnable, comme nous le verrons plus en détail dans les applications, section 4.2. L’algorithme se termine par une dernière étape d’équilibrage des charges, en déplaçant une nouvelle fois les interfaces entre les sous-domaines (figure 3.1.7).
GMRES + Multigrille
Le préconditionneur multigrille a été associé jusqu’à maintenant à la méthode du RésiduConjugué, particulièrement adaptée pour la résolution de systèmes symétriques et en particulier ceux obtenus dans FORGE R NxT. Afin d’étudier l’intérêt que pourraient présenter les multigrilles sur d’autres types de systèmes linéaires, nous nous intéréssons ici à une méthode de résolution plus générale, la méthode généralisée de minimisation du résidu (GMRES). Proposée par (Saad et Schultz, 1986), elle s’apparente à une généralisation de la méthode du résidu conjugué qui s’applique aux matrices non symétriques. Nous reprenons les cas issus des simulations d’écrasement entre tas plats et de forgeage du triaxe en milieu de simulation (section 2.5). Nous comparons les temps de calcul obtenus avec la méthode GMRES préconditionnée par une méthode multigrille (GMRES + MG) avec ceux obtenus en utilisant un préconditionneur ILU1 (GMRES + ILU1), considéré comme étant le plus performant pour les problèmes étudiés. Nous supposons que les conclusions établies précédemment pour définir le préconditionneur multigrille de cette étude restent valables :
– Solveur direct LU sur la grille grossière
– Lisseur PR + ILU0 avec 1 itération de pré et post lissage
– Facteurs de déraffinement homogènes
– Grille grossière proche de 500 nœuds
Solveur Multigrille
Pour terminer ce chapitre, nous étudions l’utilisation de la méthode multigrille en tant que solveur. Les motivations derrière ce développement étaient pour partie de se libérer de la « boite noire » multigrille de PETSc, afin notamment d’utiliser un critère de précision pour controler le nombre d’itérations de lissage. D’autre part, nous souhaitions comparer les performances des multigrilles en tant que solveur et préconditionneur sur nos problèmes. Pour développer ce solveur multigrille, nous utilisons toujours la librairie PETSc et l’ensemble de ses fonctions :
– Méthodes itératives de résolution pour les lissages
– Multiplication matrice-vecteur pour le transfert entre les grilles
– Multiplication matrice-matrice pour la construction des matrices grilles grossières
Nous utilisons également la librairie MUMPS pour la résolution directe sur la grille grossière. Nous utilisons une nouvelle fois les problèmes d’écrasement entre tas plats et de forgeage d’un triaxe. Nous nous plaçons dans la même configuration que celle utilisée pour l’étude du lisseur du préconditionneur, en considérant une méthode bigrille idéale. Pour l’écrasement entre tas plats, le maillage fin comporte 22 059 nœuds et le maillage grossier 902 nœuds (figures 3.6a et 3.6b). Pour le forgeage du triaxe en milieu de simulation, le maillage fin comporte 16 902 nœuds (figure 3.7a) et le maillage grossier 936 nœuds (figure 3.7b). Avec le solveur multigrille, une plus large variété de lisseurs a pu être testée. En plus des lisseurs Richardson préconditionnés par ILU0, Jacobi ou SSOR préalablement testés sur le préconditionneur (PR+ILU0, PR+Jacobi et PR+SSOR), nous avons considéré le résidu conjugué en tant que lisseur associé aux préconditionneurs ILU0, ILU1 et Jacobi (CR+ILU0, CR+ILU1, CR+Jacobi). Il résulte d’essais menés avec un nombre d’itérations de pré et post lissages allant de 1 à 5. Le nombre total d’itérations de lissage figure également dans ce tableau. Pour rappel, le temps de résolution obtenu avec le préconditionneur multigrille dans sa configuration quasi optimale (lisseur PR+ILU0 (1,1)) est de 9,59 secondes. Le premier résultat marquant est que pour tous les lisseurs, le meilleur résultat est obtenu d’un écrasement entre tas plats par le solveur multigrille avec différents lisseurs avec une combinaison demandant plus d’itérations de post lissage que de pré lissage. Dans son utilisation en tant que solveur, le post-lissage joue un rôle plus important et permet de limiter le nombre de cycles multigrilles. Comme dans son utilisation en tant que préconditionneur avec lisseur de type Richardson, le lisseur Résidu Conjugué préconditionné par ILU1 donne des temps de calcul largement supérieurs aux autres, à cause d’un coût de factorisation et de résolution trop élevés et malgré un nombre d’itérations assez faible. Le lisseur SSOR donne de moins bons résultats que les autres lisseurs, comme observé dans l’utilisation des multigrilles en tant que préconditionneur. Le solveur utlisant le lisseur CR+ILU0 se révèle étonnament plus efficace, et présente des résultats bien meilleurs que ceux obtenus en préconditionnement (7,1 s au lieu de 9,59 s).
|
Table des matières
Introduction générale
1 Méthodes Multigrilles
1.1 Présentation
1.1.1 Principe
1.1.2 Méthode bigrille
1.1.3 Méthodes multigrilles
1.2 Multigrilles Algébriques (AMG)
1.3 Multigrilles Géométriques (GMG)
1.3.1 Grilles emboitées par élément
1.3.2 Grilles emboitées par noeud
1.3.3 Grilles indépendantes
1.4 Bilan et approche retenue
2 FORGE R
2.1 Modélisation du problème mécanique
2.1.1 Equations
2.1.2 Eléments Finis Mixtes
2.1.3 Discrétisation
2.2 Résolution numérique du problème mécanique
2.2.1 Système à résoudre
2.2.2 Méthode de résolution
2.3 Génération de maillage et remaillage
2.3.1 Mailleur topologique MTC
2.4 Calcul Parallèle
2.4.1 Stratégie SPMD
2.4.2 Partitionnement et remaillage
2.5 Simulations de référence
2.5.1 Ecrasement entre tas plats
2.5.2 Triaxe frottant avec repli
2.5.3 Laminage retour
2.5.4 Martelage rotatif
3 Méthode Multigrille pour FORGE R
3.1 Méthode multigrille hybride
3.1.1 Construction parallèle des maillages grossiers
3.1.2 Construction parallèle des opérateurs de transfert
3.1.3 Eléments complémentaires
3.2 Réglage du préconditionneur Multigrille
3.2.1 Lisseur
3.2.2 Facteur de déraffinement
3.2.3 Grille grossière
3.3 Extensions de la méthode multigrille
3.3.1 GMRES + Multigrille
3.3.2 Solveur Multigrille
3.4 Conclusion
4 Etude de performances et applications
4.1 Etude de performances
4.1.1 Complexité asymptotique
4.1.2 Calcul parallèle
4.2 Applications
4.2.1 Forgeage du Triaxe
4.2.2 Laminage retour
4.2.3 Martelage rotatif
4.3 Conclusion
Conclusions et Perspectives
Bibliographie
![]() Télécharger le rapport complet
Télécharger le rapport complet