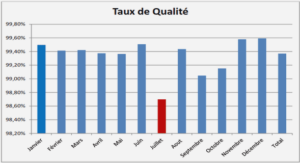
Chaîne de Markov de mobilité
Une chaîne de Markov de mobilité (CMM) [GKNndPC11a] modèle le comportement de la mobilité d’un individu comme un processus stochastique discret dans lequel la probabilité de passer d’un état (i.e., POI) á un un autre ne dépend que de l’état précédemment visité et de la distribution de probabilité sur les transitions entre états. Plus précisément, une CMM est composée de:
• Un ensemble d’états P ={P1,…P n }, dans lequel chaque état est un POI fréquent (classés par ordre décroissant d’importance), il y peut avoir une exception par rapport au dernier état p n qui peut correspondre à l’ensemble composé de tous les POI peu fréquentés. Les POIs sont extraits en exécutant un algorithme de clustering sur les traces de mobilité d’un individu. Ces états sont associés à un lieu, et généralement ils ont aussi une signification sémantique intrinsèque. Par conséquent, les étiquettes sémantiques telles que “maison” ou “travail” peuvent souvent être déduites et attachées à ces états.
• Transitions, comme ti,j , représentant la probabilité de passer de l’état p i à l’état Pj . Une transition d’un état à lui-même n’est possible que si l’individu a une probabilité non nulle de passer d’un état à un emplacement occasionnel avant de revenir à cet état. Par exemple, un individu peut quitter la maison pour aller à la pharmacie et ensuite revenir à son domicile. Dans cet exemple, il est probable que la pharmacie ne soit pas extraite comme un POI par l’algorithme de clustering, sauf si la personne se rend à ce lieu sur une base régulière et y reste pendant un temps considérable.
Il faut noter que plusieurs modèles de mobilité basés sur les chaînes de Markov ont été proposés dans le passé [GKNndPC11a, AS03], y compris l’utilisation de modèles de Markov cachés pour extraire la sémantique des POIs [YCP + 11a]. En un mot, la construction d’une CMM est un processus en deux étapes. Pendant la première phase, un algorithme de clustering est exécuté pour extraire les POI des traces de mobilité. Par exemple, dans le travail de Gambs et al. [GKNndPC11a], un algorithme de clustering appelé Density-Joinble Cluster (DJ-Cluster)a été utilisé (nous nous appuyons sur le même algorithme dans ce travail), mais bien sûr d’autres algorithmes de clustering sont possibles. Dans la deuxième phase, les transitions entre ces POIs sont calculées et intégrées dans le CMM.
DJ-Cluster prend en entrée un ensemble des traces de mobilité en plus de trois paramètres: le nombre minimal de points MinPts nécessaires pour créer un cluster, le rayon maximum r du cercle dans lequel les points d’un cluster doivent être délimités et le nombre minimal de jours pour considérer un point d’intérêt à être fréquents. DJ-Cluster fonctionne en trois phases. Pendant la première phase, qui correspond à une étape de prétraitement, toutes les traces de mobilité dans lequel l’individu se déplace à une vitesse supérieure à une petite valeur prédéfinie ainsi que des traces redondantes sont supprimées. En conséquence, seules les traces statiques sont conservées. La deuxième phase consiste dans le clustering elle-même: toutes les traces restantes sont traitées afin d’extraire les clusters qui ont au moins MinPts des points à l’intérieur d’un rayon r du centre du cluster. Enfin, la dernière phase fusionne tous les groupes qui ont au moins une trace en commun. Une fois les POIs (i.e., les états de la chaîne de Markov) découverts, les probabilités des transitions entre les états peuvent être calculées. Pour réaliser cela, la piste des traces de mobilité est examinée dans l’ordre chronologique et chaque trace de mobilité est étiquetée avec une étiquette, soit le numéro d’identification d’un état particulier de la CMM, soit la valeur “inconnu”. Enfin, quand toutes les traces de mobilité ont été étiquetées, les transitions entre états sont comptées et normalisées par le nombre total de transitions afin d’obtenir les probabilités de chaque transition. Une CMM peut être représentée par une matrice de transition ou un graphe (cf., Figure 2) dans lequel les nœuds correspondent à des états et les flèches représentent les transitions entre les états et leur probabilité associée. Lorsque la CMM est représentée comme une matrice de transition de taille n × n, les lignes et les colonnes correspondent à des états de la CMM tandis que la valeur de chaque cellule est la probabilité de transition associée entre les états correspondants.
Prédire les mouvements
Afin de prédire le prochain emplacement sur la base des n dernières positions dans le modèle CMM, nous calculons une forme modifiée de la matrice de transition dont les lignes représentent les n dernières positions visitées. Ainsi, l’algorithme de prédiction a besoin en entrée des n derniers précédents endroits visités en plus du modèle de mobilité CMM. L’algorithme trouve la ligne correspondant à ces n emplacements précédents et recherche la transition la plus probable (les jeux décisifs sont rompus arbitrairement). S’il y a plus d’une colonne avec la même probabilité maximale, nous choisissons au hasard l’une d’entre elles.
Prédire les mouvements
Evaluation expérimentale
Dans cette sous-section, nous présentons les expériences menées pour évaluer la précision de l’algorithme de prédiction et la prédicatabilité théorique d’utilisateurs. Dans ces expériences, nous avons utilisé trois ensembles de données différents: Arum (phonétique), Geolife et synthétique, dont les caractéristiques sont résumées dans le Tableau 1.2 de la Section 1.2.4. Afin d’évaluer l’efficacité de nos prédicteurs de localisation, nous calculons deux mesures: la précision et la prédicatabilité. La précision Acc est le rapport entre le nombre de prédictions correctes p correct et le nombre total de prédictions p total : Prcision = p correctes /p total . (1) La prédicatabilité pred est une mesure théorique qui représente la mesure dans laquelle la mobilité d’un individu est prévisible en fonction de son CMM (dans le même esprit que le travail de Barabasi et co-auteurs [SQBB10]). Par exemple, si la prédiction de l’emplacement sait que Bob était au travail (W ) et qu’il est actuellement à la maison (H), la probabilité de faire une proposition réussie est théoriquement égale à la transition de probabilité sortant maximale, qui est 84 % pour cet exemple particulier (voir le Tableau 4.3). Plus formellement, la prédicatabilité Pred d’une CMM particulier (et donc une personne en particulier) est calculé comme la somme des produits entre chaque élément du vecteur stationnaire π du modèle CMM, ce qui correspond à la probabilité d’être dans un état particulier (pour l, le nombre total d’états de cette CMM) et la probabilité sortant maximal (Pmax_out ) de l’état k e : Pred = l ∑ k=1 (π(k)× Pmax_out (k, ∗)).
Dans nos expériences, nous avons divisé chaque ensemble des traces de mobilité en deux groupes de même taille: l’ensemble d’apprentissage, utilisé pour construire la CMM, et l’ensemble d’entraînement, utilisé pour évaluer la précision du prédicteur. Enfin, nous calculons aussi le score moyen de la prédicatabilité pour chaque utilisateur en fonction de la CMM La Figure 3 montre les résultats obtenus pour un utilisateur à partir de l’ensemble de données Geolife avec n allant de 1 à 4 . Comme prévu, la précision s’améliore lorsque n augmente mais elle semble se stabiliser ou même diminuer légèrement lorsque n > 2. En outre, alors que sans surprise la précision de la prévision est généralement meilleure sur l’ensemble d’entraînement que sur l’ensemble de test , cette différence n’est pas significative. Cela semble indiquer que le comportement de mobilité d’un individu est similaire entre la deuxième partie de son ensemble de traces (le jeu de test) et la première partie de la trace (l’ensemble d’entraînement). Cela n’est pas nécessairement le cas si le comportement d’un utilisateur change naturellement en raison d’un changement important dans sa vie. Enfin, la Figure 4 affiche les résultats obtenus pour tous les utilisateurs des trois ensembles de données différents. Pour résumer, les résultats montrent de façon constante que la précision et la prédicatabilité sont optimales (ou presque optimales) lorsque n = 2, avec une précision et prédicatabilité allant de 70% à 95%. Comme nous pouvons le voir dans les deux métriques dans les ensembles de données Arum (Phonetic) et Geolife où ont tendance à suivre la même forme de la courbe décrite à la Figure 3. Le meilleur score est obtenu lorsque nous utilisons une CMM de deuxième ordre et en diminuant lorsque n tend à augmenter. Néanmoins, pour l’ensemble de données synthétique le score des deux indicateurs augmente lorsque n devient plus grand parce que nous observons les mêmes événements particuliers.
Les résultats expérimentaux
La mise en œuvre de l’inférence d’extraction sémantique est double. D’une part, nous nous appuyons sur une heuristique appelée début-fin, afin de trouver la maison [GKNndPC10a].
L’attaque a été réalisée sur les données des taxis de San Francisco et elle consiste à analyser les premières et dernières traces GPS en plusieurs jours, en se basant sur le fait que les conducteurs de taxi mettent en marche et atteignent leur GPS, quand ils partent et arrivent à la maison. Comme nous pouvons le voir dans la Figure 5, en utilisant cette attaque, nous avons localisé la maison de certains conducteurs de taxi. L’inconvénient de l’ensemble de données est l’absence de réalité de terrain. Par conséquent, nous devons vérifier manuellement la maison des conducteurs de taxi, afin de trouver des preuves de la pertinence de l’attaque. Dans le bas de la Figure 5 nous avons trouvé, en utilisant Google Street View, un taxi garé dans une impasse où nous avons trouvé la maison d’un conducteur de taxi. Cet élément de preuve ainsi que la logique derrière l’attaque début-fin démontre la capacité de l’attaque.
D’autre part, la chaîne de Markov de mobilité (CMM), peut être utilisée pour déduire le domicile et le lieu de travail des utilisateurs. Par exemple, nous prenons la CMM dans la Figure 6, qui est le modèle de mobilité de Bob. D’une part, l’état “2” (i.e., Home[2_A] dans le graphe de la Figure 6) est un état central d’où Bob peut atteindre presque tous les états. En outre, à partir de presque tous les autres états, il est possible de passer à l’état “2”. En conséquence. Nous pouvons donc en déduire que cet état correspond à la maison. D’autre part, nous pouvons prendre les deux plus grandes valeurs du vecteur stationnaire, π = [0,02, 0,01, 0,48, 0,02, 0,02, 0,02, 0,01, 0,37, 0,05], de POI et puis ces deux endroits correspondent à la maison et au lieu de travailler, dans ce cas POI “2” est la maison et POI “7” (i.e., Home[2_A] dans le graphe de la Figure 6) est le travail.
Le dernier recours pour découvrir le sens des autres POIs pourrait être d’interroger une source de données externes, comme l’ontologie d’Open Street Map (OSMonto ). Plus précisément, pour obtenir la sémantique d’un POI représenté par son medoid, qui est composé une coordonnée latitude et longitude, nous utilisons l’API Cloudmade
pour interroger OSMonto afin d’obtenir la sémantique, comme illustré dans la CMM de la figure 6. Dans la section suivante nous allons introduire une autre attaque par inférence pour désanonymiser des utilisateurs en utilisant la mobilité comme signature.
Attaque de désanonymisation
Dans cette section, nous nous concentrons sur une forme particulière d’attaque par inférence appelée attaque de désanonymisation, par laquelle un adversaire tente de déduire l’identité d’un individu particulier derrière un ensemble de traces de mobilité. Plus précisément, nous supposons que l’adversaire a pu observer les mouvements de certains individus au cours d’une quantité non négligeable de temps (e.g., plusieurs jours ou semaines) dans le passé lors de la phase d’entraînement. Plus tard, l’adversaire accède à un ensemble de données géolocalisées différentes contenant les traces de mobilité de certains individus observés au cours de la phase d’entraînement, en plus de quelques personnes inconnues éventuellement. Ensuite, l’objectif de l’adversaire est de désanonymiser cette base de données (appelée ensemble de test) en la reliant aux personnes correspondantes contenues dans l’ensemble de données d’entraînement.
Noter que en remplaçant simplement les noms réels des individus par des pseudonymes avant de libérer un jeu de données n’est généralement pas suffisant pour préserver l’anonymat de leurs identités, car les traces de mobilité elle-mêmes contiennent des informations qui peuvent être liée uniquement à un individu. En outre, tout l’ensemble de données peut être assaini en ajoutant du bruit spatial et temporel avant d’être libéré. Le risque de ré-identification par le biais l’attaque de désanonymisation existe néanmoins. Ainsi, afin d’être en mesure d’évaluer l’importance de ce risque, il est important de développer une méthode pour le quantifier.
Les distances entre les chaînes de Markov de mobilité
Dans cette sous-section, nous proposons deux distances différentes pour quantifier la similarité entre deux chaînes de Markov de mobilité. Ces distances sont basées sur différentes caractéristiques des CMMs et donnent donc des résultats différents mais complémentaires. Nous nous appuierons sur ces distances dans les sous-sections suivantes pour effectuer l’attaque de désanonymisation.
La distance stationnaire
L’intuition derrière la distance stationnaire est que la distance entre les deux CMMs peut être évaluée comme la somme des distances entre les états les plus proches des deux CMMs. Pour calculer la distance fixe, les états des CMMs sont jumelés afin de réduire cette distance. En conséquence, il est possible que l’état de la première CMM soit jumelé avec plusieurs états de la deuxième CMM (ceci est particulièrement vrai si les CMMs sont de taille différente).
Par ailleurs, le calcul de la distance repose en grande partie sur les vecteurs stationnaire des CMMs. Plus précisément, le vecteur stationnaire d’une CMM est un vecteur colonne V , obtenu en multipliant plusieurs fois un vecteur initialisé uniformément V initialisation par la matrice de transition M jusqu’à convergence (i.e., jusqu’à ce que la distribution des valeurs dans ce vecteur attend la distribution stationnaire de la CMM).
La distance stationnaire est directement calculée à partir des vecteurs stationnaires de deux CMMs (d’où son nom). Plus précisément, étant donné deux CMMs, les matrices de transition M1 et M2, les vecteurs stationnaires V 1 et V 2 de chaque modèle sont calculés, respectivement. Ensuite, l’Algorithme 1 est exécuté sur ces deux vecteurs fixes. Pour chaque état en V 1 , l’algorithme recherche l’état le plus proche en V 2 , puis il multiplie la distance entre ces deux états par la probabilité correspondante du vecteur stationnaire l’état de V 1 considéré.
Une fois que l’algorithme a pris en compte tous les états de V 1 , la valeur calculée représente la distance à partir de M1 vers M2 (distance AB ). Cette distance n’est pas symétrique en tant que tel. Par conséquent, afin de la symétriser, Algorithme 1 est appelé une fois de plus, mais sur V 2 et V 1,pour obtenir la distance à partir de M2 vers M1 (distance BA ). Le résultat est symétrique en calculant la moyenne de ces deux distances.
Mesurer l’efficacité des de-anonymizers
Pour mesurer le taux de réussite des de-anonymizers, nous avons échantillonné l’ensemble de données de Geolife à des taux différents et nous avons observé l’influence de l’échantillonnage sur le taux de réussite des dé-anonymizers. La Figure 7 montre que le taux de réussite de l’attaque avec la distance stationnaire minimale et la distance de proximité minimale varie de 20% à 40%, mais que le meilleur prédicteur est stat-prox avec des résultats allant de 35% à 40%.
À ce stade des expériences, il semble important de pouvoir comparer précisément les deanonymizers. En effet, le taux de réussite d’une attaque de désanonymisation n’est pas le seul aspect qui doit être pris en considération. Par exemple, une stratégie possible pour chaque adversaire est de se concentrer sur les personnes faibles qui offrent une forte probabilité de réussite de l’attaque plutôt que d’être capable de désanonymiser l’ensemble des données. La mesure de la probabilité de réussite de l’attaque par inférence pour un individu donné est semblable à avoir une sorte de mesure de confiance pour un candidat desanonymisé. L’issu de cette mesure de confiance est assez intuitive pour nos de-anonymizers. En effet, pour la distance minimale, plus faible est la distance, plus haute est la confiance.
Afin de comparer la performance des de-anonymizers, nous nous appuyons sur la notion de Receiver Operating Characteristic (i.e., courbe ROC) [Faw06]. En un mot, une courbe ROC est une esquisse graphique représentant la sensibilité (i.e., le rapport entre le taux de vrais positifs et le taux de faux positifs) pour un classificateur. L’intuition derriére cette métrique est que quand deux de-anonymizers atteignent le même taux de réussite, il faut privilégier celui qui possède la plus grande confiance. Désormais, la soi-disant courbe ROC qui (Figure 8) montre le taux de vrai positifs (TPR) par rapport au taux de faux positifs (FPR) pour la meilleure exécution des de-anonymizers, avec les candidats classés par ordre croissant. Cette courbe ROC confirme en outre que le de-anonymizer stat-prox est la meilleure alternative parmi les de-anonymizers que nous proposons.
Notre approche donne de bons résultats pour l’ensemble de données de Geolife où le taux de succès obtenu est entre 35% et 45% pour le de-anonymizer stat-prox. Afin de valider davantage l’approche, nous l’avons appliquée sur l’ensemble de données Nokia. Cette base de données dispose de 195 utilisateurs, parmi lesquels nous pouvons générer un CMM “ valide” composé de plus d’un POI pour 157 utilisateurs. La Figure 9 montre que le taux de réussite varie entre 35% et 42%, avec le meilleur score obtenu à nouveau par le de-anonymizer statprox.
|
Table des matières
List of Tables
Résumé F-1
1 Introduction
2 Classification des attaques par inférence
3 Chaîne de Markov de mobilité
4 Prédire les mouvements
4.1 Evaluation expérimentale
5 Extraction de la sémantique des POI
5.1 Les résultats expérimentaux
6 Attaque de désanonymisation
6.1 Les distances entre les chaînes de Markov de mobilité
6.2 De-anonymizers
6.3 Expériences
7 Conclusion
Foreword
Introduction
Chapter 1 Geo-privacy
1.1 Privacy
1.1.1 Privacy regulation
1.1.2 Inference attack
1.2 Location
1.2.1 Location Data
1.2.2 Location-Based Services
1.2.3 Economical value of mobility traces
1.2.4 Dataset description
1.3 Location privacy
1.4 Privacy leak
1.4.1 Inference Attacks on Geolocated Data
1.4.2 Inference Techniques
1.5 Classification of inference attacks
1.5.1 Identification of Points of Interests
1.5.2 Next place prediction
1.5.3 De-Anonymization attacks
1.5.4 Extracting the semantic of POIs
1.5.5 Discovering the social graph
1.5.6 Predicting demographic attributes
1.6 Geosanitizaton mechanisms
1.7 Data utility
1.8 Summary
Chapter 2 Extraction of points of interest
2.1 Related work on POI extraction techniques
2.1.1 Extraction via heuristics
2.1.2 Extraction through clustering algorithms
2.2 Clustering algorithms for extraction of points of interest
2.2.1 Density Joinable cluster
2.2.2 Density Time cluster
2.2.3 Time Density cluster
2.2.4 Begin-end heuristic
2.3 Evaluation of performance and resilience to sanitization
2.4 Cluster quality index
2.4.1 Intra-inter cluster ratio
2.4.2 Additive margin
2.4.3 Information loss
2.4.4 Dunn index
2.4.5 Davis-Bouldin index
2.5 Selecting the optimal parameters for clustering
2.5.1 Precision, recall and F-measure
2.5.2 Experimental results
2.6 Summary
Chapter 3 Mobility Markov chain and GEPETO
3.1 Mobility Models
3.2 Mobility Markov chain
3.3 GEPETO
3.3.1 GEPETO Design
3.3.2 GEPETO Implementation
3.4 Mapreducing GEPETO
3.4.1 Clustering algorithms
3.4.2 Sanitization techniques
3.5 Summary
Chapter 4 Next place prediction and semantic inference
4.1 Prediction
4.1.1 Related Work
4.1.2 Next Place Prediction
4.1.3 Experimental Evaluation
4.2 Extraction of the semantics of POIs
4.2.1 Related Work
4.2.2 Experimental results
4.3 Summary
Chapter 5 De-anonymization and linking attack
5.1 Related work
5.2 Distances between mobility Markov chains
5.2.1 Stationary distance
5.2.2 Proximity distance
5.2.3 Matching distance
5.2.4 Density-based distance
5.3 De-anonymizers
5.4 Experiments
5.4.1 Analysis of the characteristics of the datasets
5.4.2 Fine-tuning clustering algorithms and de-anonymizers
5.4.3 Measuring the efficiency of de-anonymizers
5.4.4 Fair comparison with prior work
5.5 Summary
Chapter 6 Conclusion and Perspectives
6.1 Conclusion
6.2 Perspectives
Appendix A Actors of privacy
Appendix B Resume of the state of the art and datasets used to perform inference attacks
Bibliography