Télécharger le fichier pdf d’un mémoire de fin d’études
Les différentes appellations de l’Industrie 4.0
La figure 2.2 indique le nombre de publications scientifiques parues depuis l’ap-parition du terme Industry 4.0 (2011). Nous nous sommes basés sur une requête « GoogleScholar » comprenant les termes : Industrie du futur, Industry 4.0, Industrie 4.0, Smart Factory, Industrial Internet, etc,.. Jusqu’en 2019, le terme allemand 1.In-dustrie 4.0 est le plus adopté, ce qui peut s’expliquer par le fait que le gouvernement allemand est le premier à avoir lancer l’initiative d’adopter la quatrième révolution industrielle.
Depuis 2017, de nombreux chercheurs d’autres pays commencent à travailler sur ce domaine (voir par exemple CHIARELLO et al., 2018) et attribuent l’appellation :
Malgré ces appellations dominantes, la figure 2.2 montre plusieurs noms qui sont utilisés pour décrire cette révolution comme : 3. Industrie du futur en France, qui existe depuis 1989 mais qui fait référence à d’autres thèmes de recherche. Les autres appellations sont moins utilisées. 4. Industrial Internet aux États-Unis, 5. Internet+ en Chine et en Corée (RÖPKE et al., 2016). Ce concept est également appelé « Smart Factory » ou « Integrated Industry » (HENG, 2014). Dans la suite de ce manuscrit, le terme « Industrie 4.0 » sera utilisé pour désigner la quatrième révolution industrielle.
Définition
La littérature contient plusieurs définitions de l’Industrie 4.0 qui diffèrent d’une institution à une autre et d’un auteur à un autre. Dans ce paragraphe nous allons en présenter quelques-unes, qui nous semblent les plus pertinentes. D’après la NIST (National Institute of Standards and Technology), la définition de l’Industrie 4.0 est la suivante : « les systèmes de fabrication intégrés et collaboratifs qui répondent en temps réel aux exigences et aux conditions changeantes de l’usine, du réseau d’ap-provisionnement et des besoins des clients ». Cela signifie que ce paradigme peut réagir en temps réel à une situation de fabrication compliquée et diversifiée (NIST., 2020). Ce terme très récent, qui se répète souvent dans les articles parcourus, se réfère à la quatrième révolution industrielle, est souvent considéré comme l’application du concept générique des systèmes cyber-physiques (CPS) aux systèmes de produc-tion industrielle (systèmes de production cyber-physique) (DRATH et HORCH, 2014). L’Industrie 4.0 peut aussi décrire un CPS orienté vers la production, qui intègre les installations de production, la logistique et même les processus de création de va-leur globale (WANG et al., 2016). Cette quatrième révolution, est également appelée
« usine intelligente », où l’on trouve les concepts de CPS et d’IoT, qui convergent vers l’Internet des services qui utilisent largement l’approche basée sur le Cloud computing pour créer, publier et partager les services (PISCHING et al., 2015). L’In-dustrie 4.0 se concentre sur la création de produits, procédures et processus intelli-gents, avec comme conséquence que les usines intelligentes deviennent capables de gérer la complexité et de fabriquer des produits plus efficacement (KAGERMANN et al., 2013). Pour d’autre chercheurs (par exemple HERMANN, PENTEK et OTTO, 2016, ou encore BOYES et al., 2018), l’Industrie 4.0 est la combinaison des technologies et des concepts, qui surveillent les processus physiques, créent une copie virtuelle du monde physique, et prennent des décisions décentralisées. En se basant sur l’IoT, les CPS communiquent et coopèrent les uns avec les autres et avec les humains en temps réel. Grâce à l’IoS (Internet of Service), des services internes et inter organisa-tions sont proposés et utilisés par les acteurs de la chaîne de valeur. L’architecture de l’Industrie 4.0 proposée par la vision allemande se repose principalement sur l’IoT, l’IoS, les CPS, le Big data, le Cloud computing et les capteurs (KANG et al., 2016). Les États Unis ont adopté le même concept, en rajoutant le sustainable manufacturing (énergie intelligente et l’intégration des systèmes) et la standardisation aux compo-santes européennes. Par contre, en Corée du Sud, les politiques étaient convaincus par la nécessité d’intégrer les hologrammes et la réalité augmenté dans la notion d’Industrie 4.0 (ibid.). Cette quatrième révolution industrielle, est souvent considérée comme l’applica-tion du concept générique de CPS aux systèmes de production (SCHUH et al., 2014a). D’après la littérature, nous pouvons constater que toutes les définitions partagent plusieurs aspects. Nous les prenons en considération et proposons la définition sui-vante : » L’Industrie 4.0 est un concept émergeant, qui regroupe différentes technologies existantes mais insuffisamment utilisées comme les CPS, l’IoT, l’IoS, le Cloud computing et les RMS (Reconfigurable Manufacturing System) pour rendre les industries de plus en plus intelligentes, efficaces, sécurisées, distribuées et fonctionnant en temps réel. Par conséquent cela va conduire les industries à un autre niveau d’optimisation en terme de coûts, délai et qualité. ».
Les exigences de l’Industrie 4.0
Comme présenté auparavant, le Cloud Manufacturing est l’une des solutions les plus importantes proposées pour résoudre le problème du cumul d’une grande quantité de données complexes. Néanmoins, cette solution souffre de plusieurs limi-tations dans ce nouveau contexte d’Industrie 4.0. Le CM ne permet toujours pas de satisfaire les exigences de l’Industrie 4.0 comme le Cloud computing en termes du temps réel, d’interopérabilité, de la sécurité des communications, etc . . .. Plusieurs projets ont discuté des exigences de l’Industrie 4.0, comme (GRANGEL-GONZÁLEZ et al., 2016), qui décrit une approche qui représente sémantiquement les informa-tions de l’Industrie 4.0. En conséquence, (LOM, PRIBYL et SVITEK, 2016, KHAN et al., 2017, WAIDNER et KASPER, 2016, SALDIVAR et al., 2015) détaillent les exigences ou les principes de conceptio » sur lesquels se basent la création des applications d’In-dustrie 4.0 qui pourraient être basées sur le Cloud computing :
— Fiabilité,
— Administration des actifs Shell (normalisation, sémantique, interopérabilité),
— Communication (capacité d’échange en temps réel, protocoles de transfert de données, QoS adaptative dynamique, latence, bande passante),
— Considérations de sécurité (authentification, politiques de confidentialité, contrôle d’accès),
— Optimisation,
— Capacité d’analyse des données,
— Interactions homme-machine.
— Virtualisation
— Décentralisation
— Orientation du service
— Modularité
Les exigences de l’Industrie 4.0 doivent permettre d’assurer le bon fonctionne-ment du processus de production et ainsi un haut niveau de performance des appli-cations industrielles ( maintenance, planification, diagnostic, supervision, etc.)
Comme l’Industrie 4.0 a comme objectifs d’augmenter les profits et la qualité et de minimiser le coût de la fabrication, chaque technologie proposée afin d’intégrer les composants déjà existants de l’Industrie 4.0 doit certainement être en mesure de répondre à ces exigences.
La nouveauté dans la proposition de l’Industrie 4.0 n’est pas dans une nouvelle technologie, mais dans la combinaison des technologies disponibles d’une nouvelle façon (DRATH et HORCH, 2014). Le quadruplet (IoT, IoS, CPS et Cloud) et l’avenir de la production de biens physiques sont dépendants, ce qui entraîne que ces com-posants offrent un énorme potentiel d’innovation dans la production.
Ce paradigme prometteur conduit aux nombreux résultats bénéfiques qui peuvent faire face aux défis mondiaux en ce sens que les produits personnalisés peuvent être produits de manière efficace, efficiente, flexible et rentable (WANG et al., 2016).
Conformément au contexte de l’Industrie 4.0, les produits peuvent contrôler leur propre processus de production et le client devrait être plus impliqué dans les pro-cessus de création de nouveaux produits (PISCHING et al., 2015). Avec l’Industrie 4.0, il sera possible d’intégrer des fonctionnalités spécifiques aux clients et aux produits dans les phases de conception, de configuration, de commande, de planification, de production, d’exploitation et de recyclage. Cela fournira des produits personnalisés d’une manière rentable. L’Industrie 4.0 permettra aux employés de contrôler, réguler et configurer les ressources et les étapes de production. La réussite d’intégrer les ser-vices Web dans l’Industrie 4.0 et la portée du potentiel de cette technologie prédisent une augmentation considérable de son utilisation (KAGERMANN et al., 2013).
Problématique générale
Dans cette section, nous allons tout d’abord expliquer notre contexte industriel pour délimiter le périmètre général de cette thèse. La question importante qui peut-être posée par les industriels concerne le potentiel de performances du Cloud com-puting. Les questions de la problématique générale qui se posent sont : si le Cloud computing n’est plus la solution optimale, quels sont les facteurs qui ont causé une telle limitation ? Quelle est la meilleure solution afin de renforcer le rôle du Cloud computing dans le domaine industriel et plus spécifiquement dans le contexte de l’Industrie 4.0 ? Et par la suite pour finir cette section nous présentons le positionne-ment technique et scientifique de la thèse.
Contexte
Les éléments constitutifs de l’Industrie 4.0 doivent satisfaire ses exigences afin d’assurer un haut niveau de fonctionnement et d’intelligence. Le manque de perfor-mances du Cloud computing est problématique devant les besoins des applications industrielles actuelles. L’intégration de nouvelles technologies qui se base sur le trai-tement des données et sur l’IoT semble la solution la plus adaptée pour répondre à ces limitations du Cloud computing et du Cloud Manufacturing. Le développement de l’Industrie 4.0 est l’un des enjeux prioritaires fixés par l’Europe dans les nou-veaux programmes de recherche. Actuellement l’Industrie 4.0 est l’un des thèmes de recherche et de formation dans le cadre de la Chaire CISCO / CESI / Vinci Energies intitulée « Industrie et Services de demain ».
Dans les parties précédentes nous avons présenté le paradigme de l’Industrie 4.0, en évoquant son historique, ses composantes et ses exigences. L’Industrie 4.0 est une usine fortement connectée. Les machines et produits peuvent échanger des données pour élaborer leurs différentes tâches. Des quantités importantes d’informations va-riées sont générées et remontées chaque seconde par les différents capteurs installés au sein de l’atelier de production que ce soit dans les outils de production, le système logistique ou les services annexes. Ces informations doivent être collectées et traitées en temps réel afin d’assurer un bon fonctionnement du système de production. Les systèmes centralisés qui collectent et traitent les données (Le Cloud computing) ont montré leurs limites quand il s’agit du traitement d’un très grand nombre de don-nées et de prises de décision en temps réel.
Cependant, les systèmes distribués ont prouvé leur efficacité pour la gestion des systèmes complexes en général et plus particulièrement les systèmes de production complexes (TRENTESAUX, 2009). Pour cela, il faut décentraliser le traitement des données ainsi que la prise de décision tout en assurant une bonne interopérabilité entre les différentes ressources des systèmes.
L’adoption et la mise en œuvre de l’Industrie 4.0 sont soumises à plusieurs défis, tels que :
— Le manque de transmission en temps réel et de mises à jour d’informations concernant les ressources de production en cours du processus de fabrication,
— L’augmentation du temps d’attente (délais) entre la détection d’un problème, la planification ou l’ordonnancement des tâches et la prise d’une décision fiable,
— La garantie d’un niveau respecté de sécurité et de confidentialité des res-sources de production des industriels et les informations liés aux clients,
— L’urgence d’être prêt à faire face à tout type de concurrence et aux change-ments soudains du marché (adoption d’une politique de production flexible et dynamique afin d’augmenter les profits et diminuer le coût).
Le rôle et l’intérêt du Cloud Computing dans les applications indus-trielles
La cause majeure des problèmes limitant l’adoption de l’Industrie 4.0 est la quan-tité croissante de données, de plus en plus difficiles à traiter et à échanger (LEE, KAO et YANG, 2014). Comme cette quantité de données va continuer à croître suivant le nombre croissant des objets connectés, un nouveau phénomène gênant pour les centres de données peut arriver en impactant les performances et en créant une crise du stockage (ZANDER et MÄHÖNEN, 2013). Ce phénomène, connu sous le nom de « tsunami des données », peut également affecter les installations industrielles et no-tamment leurs réseaux informatiques non dimensionnés pour ces nouveaux besoins. Cette nouvelle génération de systèmes de production commence à générer une énorme quantité de données complexes tout au long du cycle de vie du produit et de la chaîne de valeur. Pour contrôler ce flux d’informations, plusieurs améliorations, réglages et traitements doivent être effectués.
Malheureusement le Cloud, qui est basé sur le traitement de l’information sur demande, n’est pas adéquat pour les applications sensibles à la latence. Par consé-quent il ne peut pas couvrir les besoins de ce genre des applications basées sur l’IoT (PISCHING et al., 2015). Donc le manque de liaison entre les différentes parties et l’in-suffisance du rendement du Cloud computing, qui est distant, centralisé et avec des risques de latence de traitement, représentent de vrai problèmes qu’il faut résoudre lors de l’implémentation et le fonctionnement des usines de futur.
Ajouté à cela, les risques liées à la cyber-sécurité ou à l’augmentation incontrôlée de la complexité des systèmes (des données dépassant la capacité du système de traitement) existent. L’une des solutions les plus intéressantes qui peuvent résoudre ce genre de problème semble être l’edge computing et ses déclinaisons. Ce nouveau paradigme va être présenté et détaillé dans la section suivante.
Edge computing – solutions existantes et déclinaisons
Les applications utilisées soit par les industries soit dans d’autres domaines ap-plicatifs souffrent de la sensibilité à la latence des réponses ou de la prise de déci-sion quand elles regroupent un grand nombre de nœuds connectés qui ne cessent de croître à une fréquence très rapide. Afin de gérer ces besoins, les applications se basent sur l’IoT et le Cloud computing afin de traiter, acheminer et stocker les données générées. D’après ce qui est conclu dans la section précédente, le Cloud computing ne semble plus efficace devant les exigences croissantes des applications basées sur l’IoT et le Cloud computing.
La solution qui peut résoudre une telle problématique c’est de diminuer le temps de transmission (envoie de demande, traitement et réponse) et de distribuer le cal-cul sur le plus grand nombre de dispositifs connectés possible. Cette solution doit satisfaire les besoins suivants :
— Être basé sur l’IoT,
— Étendre les fonctionnalités du Cloud computing,
— Être compatible avec le modèle de calcul du Cloud computing,
— Être évolutif en face du nombre grandissant des nœuds qui composent l’ar-chitecture de l’application,
— Respecter les faibles latences exigées par les applications,
— Distribuer le calcul tout le long du réseau,
— Être à proximité de la couche la plus basse afin de diminuer les délais. L’Edge computing se réfère aux technologies qui traitent les données à proximité
des utilisateurs finaux. Ce modèle de calcul fournit les ressources du Cloud com-puting au bord du réseau (PAN et MCELHANNON, 2017, SATYANARAYANAN, 2017). La localisation et les capacités de l’Edge computing semblent être une solution aux limitations des serveurs centralisés du Cloud computing.
Par contre, l’Edge computing est considéré comme la technologie mère, ce qui reste très vaste. Donc elle regroupe de nombreuses particularités, qui dépendent de l’application ou du domaine de l’utilisation. En étudiant la littérature, différentes déclinaisons de l’edge computing ont été identifiées:
— Les Cloudlets,
— Le Mobile Edge Comuting,
— Le Fog Computing.
Dans ce qui suit une brève description de chaque déclinaison de l’Edge computing, afin de décider laquelle est la plus convenable pour surmonter les limitations du Cloud computing dans le contexte d’Industrie 4.0.
Cloudlets
Le Cloudlet est un projet qui vise à rapprocher les services du Cloud compu-ting aux utilisateurs mobiles, tout en créant des « mini » centres de données virtuels et intermédiaires (PAN et MCELHANNON, 2017). Un Cloudlet est présenté comme la miniature d’un serveur Cloud computing. Cette version plus légère est implémentée généralement à proximité des utilisateurs finaux. Les Cloudlets sont installés sur une ou plusieurs machines virtuelles (VMs) afin qu’elles soient localisées et repérables. Les Cloudlets sont caractérisées par leur structure dynamique. Lorsqu’une demande de la part d’un utilisateur mobile est générée, la latence causée par la transmission au serveur du Cloud computing distant peut nuire à la QoS et interrompre la com-munication ( basée sur le WLAN). La figure 2.5 décrit l’architecture hiérarchique basée sur les Cloudlets.
L’avantage des Cloudlets est pour les utilisateurs mobiles, ils ont la possibilité d’obtenir les services personnalisés en forme d’instances des logiciels requis sur les VMs d’une manière fluide et légère (BAHTOVSKI et GUSEV, 2014). L’autre avantage est l’auto-configuration et l’autonomie des Cloudlets (SHAUKAT et al., 2016). Donc les Cloudlets sont utilisés principalement pour les utilisateurs mobiles qui auront besoin des ressources du Cloud computing sans alourdir le réseau ou dépasser les capacités limitées de leurs matériels. Donc la latence et la bande passante sont no-tamment réduites grâce à cette solution.
Malgré la faible latence des transmissions entre les Cloudlets et les utilisateurs mobiles, le calcul et le stockage des données et l’amélioration de la QoS, les Cloudlets ne peuvent pas assurer l’amélioration des performances du Cloud computing dans le contexte industriel. L’absence de communication continue avec le Cloud compu-ting, le manque d’aspect serveur de calcul local et la personnalisation spécifiques pour les utilisateurs mobiles entraînent une inadéquation avec les besoins en envi-ronnement industriel.
Mobile Edge Computing (MEC)
Le MEC est une déclinaison de l’Edge computing qui a un fonctionnement si-milaire à celui des Cloudlets. Le MEC est introduit afin de rapprocher les services du Cloud computing à proximité des utilisateurs finaux, qui sont généralement les opérateurs et clients mobiles du réseau d’accès radio (AHMED et REHMANI, 2017).
Le MEC est composé des serveurs situés à la périphérique du réseau pour faire des calculs et stockage en temps réel (BUYUKKOC, 2016). Les serveurs du MEC fonc-tionnent dans les stations de bases. Conséquemment ces utilisateurs mobiles vont profiter des communications avec de faibles latences à l’aide du support de mobilité du MEC.
Cette version, dédiée aux opérateurs des réseaux mobiles, est fortement exploitée pour satisfaire les exigences de la cinquième génération (5G) des standards pour la téléphonie mobile. Le MEC est adopté pour de nombreuses applications mobiles (la gestion du trafic, la distribution du contenu, la mise en cache du contenu en bord de réseau,etc.) La figure 2.6 présente l’architecture basée sur le MEC. La couche la plus basse est composée des nœuds mobiles et le réseau de transmission est le réseau radio.
Le MEC est spécifique pour les applications mobiles et les nœuds connectés au réseau radio restreint. Comme l’Industrie 4.0 regroupe des objets connectés à l’IoT qui est un réseau internet ouvert et général, cette version de l’Edge computing est incompatible avec le contexte des données de l’Industrie 4.0.
Fog Computing
Le Fog computing, est une solution de distribution de calcul proposée par Cisco. Il a plusieurs caractéristiques qui conviennent aux exigences de l’Industrie 4.0. Le Fog computing et ses avantages n’étaient pas bien connus à l’époque de l’apparition de l’Industrie 4.0, ce qui explique son absence comme l’une de ses composantes. Plus tard, plusieurs comparaisons ont été établies (O’DONOVAN et al., 2019) et ont prouvé le rôle important du Fog dans le contexte de l’Industrie 4.0. La plupart des travaux concernant ce genre d’étude sont apparus dans les années 2019 et 2020 (pendant les travaux de cette présente thèse).
En effet, le Fog computing est capable de faciliter la mise en œuvre du concept d’Industrie 4.0 où, il peut être adopté pour permettre l’inter-connectivité des CPS dans le cadre industriel et améliorer les fonctionnalités et les performances du Cloud computing. Ce paradigme est capable de répondre aux exigences de l’Industrie 4.0 en termes de flexibilité, de communication, d’autonomie, de sécurité, d’analyse des données en temps réel, de fiabilité (QoS), et d’interopérabilité (BAR-MAGEN NUM-HAUSER et MESA, 2013). (BACCARELLI et al., 2017) ont mentionné le rôle important que le Fog computing peut offrir pour améliorer l’Industrie 4.0 en fournissant un traitement évolutif en termes de calcul, de stockage et de routage. L’emplacement du Fog est capable de supporter le flux massif de données provenant des appareils et dispositifs connectés et de filtrer les données acheminées au Cloud computing qui est distant. Aussi, P ´ et L , 2016 ont proposé le Fog computing comme un IZON IPSKI nouveau composant qui va résoudre le problème de traitement des données pour les systèmes industriels. (GEORGAKOPOULOS et al., 2016) ont choisi la même direction en confirmant que l’ajout de l’Edge Computing est crucial pour l’Industrie 4.0 pour les mêmes raisons. Son architecture qui se base sur l’IoT est une forte raison pour laquelle le Fog com-puting semble la technologie la plus adéquate pour être un composant de l’Industrie 4.0 à côté du Cloud computing. La figure 2.7 présente l’architecture générale basée sur le Fog computing.
Le tableau 2.2 résume les caractéristiques de chaque déclinaison (Cloudlets, MEC et Fog Computing) de l’Edge computing et montre les différences entre elles. D’après ce tableau 2.2 le choix de la solution du Fog computing dans le contexte de l’In-dustrie 4.0 semble la plus susceptible d’être utilisée comme moyen de distribution des calculs, moyen de communication entre différents organes de l’atelier et support pour le cloud computing. Dans le suite de ce chapitre nous allons étudier le fog com-puting comme solution technologique pour la répartition du traitement des données dans les ateliers de production.
|
Table des matières
Résumé
1 Introduction générale 1
2 Contexte & État de l’art 5
2.1 Introduction
2.2 L’Industrie 4.0 : État de l’art
2.2.1 L’historique des révolutions industrielles
2.2.2 La relation entre les données et les révolutions industrielles
2.2.3 Les différentes appellations de l’Industrie 4.0
2.2.4 Définition
2.2.5 Composants
Internet of Things (IoT)
Cyber physical system (CPS)
Internet of Services (IoS)
Big Data
Les capteurs (Sensors)
Cloud Computing et Cloud Manufacturing
2.2.6 Intégration
2.2.7 Les exigences de l’Industrie 4.0
2.3 Problématique générale
2.3.1 Contexte
2.3.2 Le rôle et l’intérêt du Cloud Computing dans les applications industrielles
2.3.3 Edge computing – solutions existantes et déclinaisons Cloudlets
Mobile Edge Computing (MEC)
Fog Computing
2.4 Fog Computing
2.4.1 État de l’art
Définition
Les travaux intégrant le Fog Computing
Les caractéristiques
L’évolution de l’architecture
2.4.2 Du Cloud Computing au Fog Computing
2.5 Conclusion
3 Le Fog Computing dans le contexte de l’Industrie 4.0
3.1 Introduction
3.2 Étude de l’intégration du Fog Computing dans le contexte de l’Industrie 4.0
3.2.1 Le Fog Computing répond-il aux exigences de l’Industrie 4.0 ?
3.2.2 Les domaines d’application existants du Fog Manufacturing
Maintenance prédictive
Traçabilité
Monitoring
Diagnostic et pronostic
Consommation d’énergie
Logistique
Planification ou ordonnancement
3.2.3 Analyse et synthèse
3.3 Les défis limitant l’intégration du Fog computing
3.3.1 Les défis « Input »
Programmabilité (P)
Sécurité (S)
Hétérogénéité (H)
Interopérabilité (I)
3.3.2 Les défis « Output »
Qualité de Service (QoS)
Consommation d’énergie
Coût
3.3.3 Les liens entre les défis
3.4 Les possibles applications du fog computing dans le contexte de l’Industrie 4.0
3.5 Conclusion
4 Déploiement optimal du Fog Computing pour la logistique interne dans le contexte de l’Industrie 4.0 71
4.1 Introduction
4.2 La logistique dans le contexte de l’Industrie 4.0
4.2.1 Contexte
4.2.2 Problématique du déploiement du Fog Manufacturing
4.3 L’architecture du Fog Manufacturing
La couche des terminaux
La couche du Edge computing
La couche du Fog computing
La couche du passerelle
La couche du Cloud computing
4.4 L’optimisation du coût de déploiement du Fog Manufacturing
4.4.1 Paramètres
4.4.2 La fonction objectif
4.4.3 Les contraintes de base
L’activation des nœuds
La capacité de demande des nœuds
La latence des transmissions
La couverture des AGVs par les nœuds Edge
Le nombre maximal des liens supporté par un nœud
4.4.4 Nos contributions
La linéarisation
La probabilité de la capacité de réseau
Le type de lien
4.5 L’optimisation du modèle
4.5.1 La méthode exacte
4.5.2 Description des cas d’étude
4.5.3 Résolution et résultats
Le modèle sans linéarisation
Le modèle avec linéarisation & sans nouvelles contraintes
Étude de la sensibilité
Le modèle avec la contrainte de la probabilité de demande de réseau
Le modèle avec la contrainte du choix du lien
4.5.4 Perspectives
4.6 Conclusion
5 Déploiement d’une plateforme Fog Computing pour le traitement en temps réel d’un CPS de production
5.1 Introduction
5.2 Conteneurisation
5.2.1 Définition
5.2.2 Conteneurs vs. machines virtuelles
5.2.3 Les plateformes de conteneurisation
Les plateformes Linux
La plate-forme Docker
5.2.4 Moteurs d’orchestration des conteneurs
5.2.5 Exemple de moteurs d’orchestration
5.3 Conception et spécifications des besoins fonctionnels
5.3.1 Diagramme de cas d’utilisation
Description des acteurs
Diagramme de cas d’utilisation globale
5.3.2 Diagramme de séquences
5.4 Choix Technologiques
5.4.1 Les FNs : Raspberry Pi
Le choix des FNs
Evolution des cartes Raspberry Pi
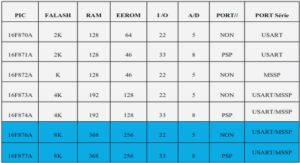
Fiche technique du Raspberry Pi3
5.4.2 Langage de programmation, Python
5.4.3 Logiciel libre de conteneurisation, Docker
5.4.4 Orchestrateur des conteneurs, Kubernetes
5.5 Connectivité
5.6 Réalisation
5.6.1 Déroulement
Première phase : sans intégration des robots
Deuxième phase : avec intégration des robots
5.6.2 Test et résultats de l’implémentation technique
Développement & Test de l’application sur une Machine Virtuelle
Création du conteneur
Déploiement de l’image dans le cluster
5.6.3 Difficultés techniques rencontrées
Communication entre les noeuds de l’architecture
Traitement temps réel
5.6.4 Perspectives
5.6.5 Conclusion
6 Conclusion générale
Télécharger le rapport complet