L’approche basée sur l’intelligence artificielle
Modèles dynamiques univariés
La modélisation univariée d’une série temporelle se fait en général à l’aide d’une régression linéaire qui inclut deux composants : un terme autorégressif (AR) qui établit un lien (généralement linéaire) entre les réalisations présentes et passées de la variable d’intérêt et une composante de moyenne mobile (MA), qui établit un lien (généralement linéaire) entre les déviations aléatoires présentes et passées entre les réalisations de la série en tous temps et les valeurs intra-échantillon prédites par le modèle. Dans notre contexte, lorsqu’un modèle purement AR(p) est utilisé pour modéliser le profil temporel de consommation d’électricité, la réalisation présente de cette variable est une combinaison linéaire des consommations observées aux p périodes précédentes auquel on ajoute une erreur de mesure aléatoire pour la période présente. L’avantage du modèle autorégressif est sa simplicité. Son inconvénient est que les méthodes autorégressives présupposent la stationnarité des séries. Une série est dite faiblement 7 stationnaire si sa moyenne,ztzEμ=)( ne dépend pas l’indice de temps t et si la covariance entre tz et ktz− dépend seulement du décalagek. Si une série est stationnaire et normalement distribuée alors, la moyenne )(zμ et la variance )(2zσsuffisent pour caractériser la série. Cependant, la covariance est importante pour l’identification des fonctions d’autocorrélation (Aragon, 2011 ; 57).
L’économétrie distingue en général deux types de non stationnarité : déterministe et stochastique. Un processus non stationnaire déterministe à la forme générale ??=?(?)+ ??, où ?(?) est une fonction déterministe du temps (t) et ?? est un terme d’erreur aléatoire de moyenne nulle, de variance finie et en général indépendant et identiquement distribué. Un processus non stationnaire stochastique est un processus explosif vis-à-vis de ses réalisations passées. Le plus connu d’entre eux est la marche aléatoire (ou processus avec une racine unitaire sans dérive), qui a la forme fonctionnelle ??=??−1 + ??. Il est facile de montrer que la variance de ce processus croît avec t. Une simple transformation des données permet en général de stabiliser les séries non stationnaires. Dans le cas de la tendance déterministe, il faudra identifier la forme paramétrique de ?(?) et la soustraire à ?? pour obtenir une transformation stationnaire de la série. Dans le cas de la tendance stochastique, la différenciation des données permet de rendre le processus stable. Notons qu’un processus peut posséder une tendance à la fois déterministe et stochastique.
Modèle de lissage exponentiel Holt-Winters
Le lissage exponentiel englobe une série de méthodes intuitives de lissage et de prévision apparues dans les années 50. Au fil des années, ces méthodes ont laissé place à des spécifications rigoureuses. Ces techniques permettent de mettre à jour les prédictions en t+1 sur la base de moyennes pondérées des valeurs passées. Dans sa version la plus simple, le lissage exponentiel s’exprime par l’équation : ??=?0??+?1??−1+?2??−2+⋯, où les poids ??≥0 peuvent être définis de nombreuses manières, voir Aragon (2011;121) pour une présentation concise. Si ?? constitue notre prévision de ? en t+1, il est intuitif d’attribuer plus de poids aux valeurs ?? récentes. Le modèle de base sous cette hypothèse attribut des poids qui décroissent exponentiellement, selon la formule ??= ?(1−?)?,?=0,1,… et 0≤?≤1, d’où l’appellation de lissage exponentiel. Plus le paramètre ? est proche de 1, plus le passé immédiat influence la prévision ??. Ce schéma de pondération conduit à l’expression équivalente ??=???+(1−?)??−1, dans laquelle la mise à jour de la prévision en t+1 s’effectue facilement dès qu’une information en t est connue, en séparant la contribution du passé lointain et du présent immédiat. Dans ce travail, nous nous concentrons sur des méthodes de lissage exponentiel de type Holt-Winters, qui permettent d’ajouter à la composante autorégressive du modèle, une tendance et une saisonnalité. Notons également que le lissage exponentiel peut s’exprimer sous la forme de modèles ARIMA spécifiques, voir à ce sujet Hyndman et al (2011, Ch.11).
Les modèles avec variables explicatives exogènes
Certaines méthodes statistiques de prévision de la consommation d’électricité basées sur les séries chronologiques utilisent la consommation passée et les valeurs courantes ou passées des variables explicatives exogènes pour prévoir la consommation courante d’électricité. La régression multiple basée sur l’estimateur des moindres carrées est la plus utilisée. Il s’agit ici de rechercher le meilleur ajustement de la variable expliqués aux variables explicatives telle que la somme des carrées de résidus soit minimisée (Weron, op. cit.;81). Ainsi, lorsqu’un processus AR(p), ARMA (p,q) ou ARIMA(p,d,q) est identifié pour modéliser une série chronologique, on peut lui ajouter des variables explicatives exogènes dont on soupçonne l’influence directe. On obtient alors des modèles appelés ARX, ARMAX ou ARIMAX. La composante X du modèle indique que le processus dépend de variables explicatives exogènes. Les méthodes de modélisation de la consommation d’électricité utilisent par exemple les variables liées aux conditions climatiques telles que la température, l’humidité, etc. Lorsque l’effet de ces variables explicatives sur la consommation est non linéaireKulahci (2011;203-261) ont présenté une méthodologie d’identification des fonctions de transfert dynamique, basée sur la théorie développée par Box et Jenkins (1969), qui permet de mieux capter les mécanismes de la relation non linéaire (« avec retard ») entre les variables explicatives et la variable expliquée. Selon ces deux auteurs, elle est définit par opposition à la régression linéaire simple qui spécifie un effet immédiat d’une variable explicative sur une variable dépendante. Plusieurs autres techniques de régression permettent de tenir compte de la sélection des variables, de la corrélation entre les variables et de l’existence des valeurs extrêmes dans les variables et les résidus : ce sont les techniques de régression robuste11, certains auteurs font appel à une fonction (non-linéaire) de transfert, qui spécifie l’incidence des processus, tels que le chauffage et la climatisation, sur la relation entre les variations des variables climatiques et de consommation d’électricité. Bisgaard et 12.
Revue des recherches et des résultats Taylor, Menezes et McSharry (2006) comparent la précision prédictive à court terme (jusqu’à un jour) de six méthodes univariées d’estimation de la demande d’électricité. Les approches analysées incluent le modèle ARIMA à double saisonnalité multiple, le lissage exponentiel pour double saisonnalité et une nouvelle méthodologie basée sur l’analyse en composantes principales. Les méthodes sont appliquées à la demande d’électricité horaire de Rio de Janeiro entre le 5 mai 1996 et le 30 novembre 1996 et à la demande pour chaque demi-heure en Angleterre et au Pays de Galles couvrant la période du 27 mars 2000 au 22 octobre 2000. La méthode de lissage exponentielle par double saisonnalité performe bien avec les deux séries puisqu’elle fournit le pourcentage de l’erreur absolue moyenne de prévision le plus faible. Il ressort également de l’étude que les approches les plus simples et robustes, qui exigent peu de connaissances spécifiques à l’industrie électrique, peuvent surpasser des modèles plus complexes.
En appliquant une méthodologie similaire à celle de Taylor et al. (2006), Taylor et McSharry (2007) ont utilisé les données intra journalière de consommation d’électricité de dix pays européens pour effectuer de la prévision à court terme. Ils définissent un modèle ARIMA, un modèle AR périodique, une extension pour double saisonnalité par lissage exponentiel de Holt-Winters et une méthode basée sur l’analyse en composantes principales. Leurs modèles qui tiennent compte de la présence d’un cycle journalier et hebdomadaire dans les données sont appliqués aux données journalières de consommation d’électricité des dix pays sur une période de trente semaines (3 avril 2005 au 29 octobre 2005). La comparaison de la performance prédictive de ces méthodes aboutit à peu de différences entre modèles. Les méthodes ARIMA et de l’analyse en composantes principales se montrent les plus performantes en terme d’erreurs absolues.
|
Table des matières
Résumé
Abstract
Liste des figures
Liste des tableaux
Liste des abréviations
Dédicace
Remerciements
Avant-propos
Introduction
1.Revue de la littérature
1.1 Revue de littérature méthodologique
1.1.1 Modèles dynamiques univariés
1.1.2 Modèle de lissage exponentiel Holt-Winters
1.1.3 Les modèles avec variables explicatives exogènes
1.1.4 L’approche basée sur l’intelligence artificielle
1.2 Revue des recherches et des résultats
2.Méthodologie
2.1 Le lissage exponentiel de Holt-Winters
2.2 Le modèle ARIMA saisonnier (SARIMA)
2.3 Le modèle ARIMA saisonnier avec variable exogènes
2.4 Procédure d’estimation des modèles SARIMA
2.4.1 Test de racine unitaire
2.4.2 Saisonnalité et identification des modèles ARIMA saisonnier
2.4.3 Prévisions et mesures de performance prédictives
3. Données
3.1 Statistiques descriptives agrégées
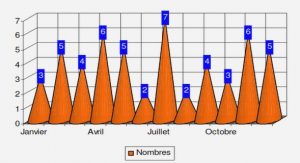
3.2 Profils chronologiques
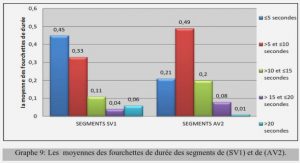
4.Résultats
4.1 Modèles de lissage exponentiel
4.2 Modèles SARIMA
4.2.1 Tests de racine unitaire
4.2.2 Estimations SARIMA
4.3 Diagnostic des modèles
Conclusion
Références bibliographiques
ANNEXE I
![]() Télécharger le rapport complet
Télécharger le rapport complet