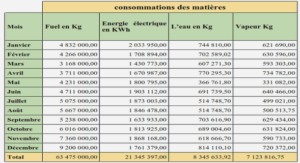
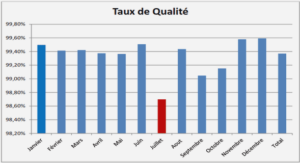
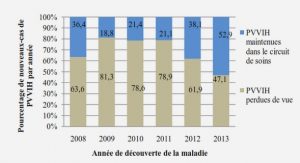
Catégorisation et taux de couverture
Régression logistique
La régression logistique multivariée telle que décrite au chapitre 2 et dont l’application a été définie dans la démarche expérimentale, aboutit en un modèle de prédiction, caractérisé par une équation, dont les variables explicatives sont les métriques orientées-objet COC, LOC et WMPC. Une équation de modèle, dans le cadre d’une régression logistique. Équation 2 – Équation du modèle de prédiction d’une régression logistique où a, b, c et d sont des coefficients, x, y et z sont les valeurs respectives des métriques COC, LOC et WMPC pour une classe donnée et E est la valeur prédite (soit de j’effort de test, soit de la couverture des tests) avec E comprise entre 0 et 1. Si E est inférieur à 0,5, alors nous l’affecterons à 0 (soit effort de
test ou couverture des tests faible), sinon 1 (soit effort de test ou couverture des tests élevée).
Stepwise
Stepwise est une procédure permettant de sélectionner la meilleure équation de régression logistique multivariée. Le Stepwise selectionforward est une procédure qui consiste à introduire une
variable indépendante, pour ensuite, à chaque variable ajoutée, réévaluer si une variable devrait, selon le critère de sortie, être éliminée de l’équation. Le processus se termine lorsqu’il n’y a plus de variable respectant les critères d’entrée et de sortie. En résultat final, on obtient les variables indépendantes retenues comme étant les plus significatives par rapport au seuil fixé. Cette procédure présente l’avantage que seules les variables les plus pertinentes sont retenues tandis que celles ayant une faible contribution dans la prédication de la variable à expliquer sont ignorées. De cette manière, on se retrouve avec un modèle composé de l’essentiel des variables retenues pour optimiser la précision et la qualité de la prédiction [Singh et al. 09]. Nous appliquerons cette méthode durant nos expérimentations pour comparer la sélection de métriques qu’elle propose, avec la sélection des métriques COC, LOC et WMPC dans la construction de nos modèles de prédiction. Pour ce faire, à partir d’un ensemble de variables explicatives constituées des métriques orientées-objet (CBO, cac, FO, NOO, DOIH, LOC, NOA, RFC, WMPC; nous ne retiendrons pas LCOM, qui présente plusieurs données manquantes), nous appliquerons la méthode Stepwise pour prédire l’effort de test et la couverture des tests et commenterons l’ensemble des métriques retenues pour les modèles de prédiction générés.
R2 de McFadden
Il s’agit de vérifier si le modèle présente une vraisemblance (LLM) ou une log vraisemblance (LLO) plus favorable. Plusieurs R2 sont proposés dans la littérature et le R2 de McFadden est l’un des plus simples à appréhender [Rosmer 00]. Lorsque la régression ne sert à rien, les variables explicatives n’expliquent rien, l’indicateur vaut O. Lorsque la régression est parfaite, l’indicateur vaut 1. Menard suggère que le R2 McFadden est le plus adapté à la régression logistique [Ménard 02].
Aire soùs la courbe ROC
L’aire sous la courbe ROC (Receiver Operating Characteristic) [Singh et al. 09], indique la précision d’un modèle de prédiction et informe sur sa performance. On désigne par sensibilité (sensivity) la proportion d’événements positifs bien classés. La spécificité (specificity) correspond à la proportion
d’événements négatifs bien classés. Si l’on fait varier la probabilité seuil (cutoff) à partir de laquelle on considère qu’un événement doit être considéré comme positif, la sensibilité et la spécificité varient. La courbe des points (1 spécificité, sensibilité) est appelée la courbe ROC. L’aire sous courbe (ou Area Under the Curve – A UC) est un indice synthétique évalué pour les courbes OC. L’AUC correspond à la probabilité pour qu’un événement positif ait une probabilité (donnée par le modèle) plus élevée qu’un événement négatif. Pour un modèle idéal, on a AUC=l, pour un modèle aléatoire, on à AUC=0.5. On considère habituellement que le modèle est bon dès lors que la valeur de l’AUC est supérieure ou égale à 0.7. Un modèle bien discriminant doit avoir une AUC
entre 0.87 et 0.9. Un modèle ayant une AUC supérieure à 0.9 est excellent [Liu et al 05, Hall 90].
Interprétation des modèles
Avant d’entamer nos expérimentations, nous allons établir les équations des modèles de prédiction de l’effort de test d’une part, et celles de la couverture des tests d’autre part, pour chacun des systèmes JFREECHART, JODA, 10 et POl. L’obtention des modèles s’est faite à l’aide de l’outil XLSTAT qui nous renseigne également sur les aires sous la courbe ROC, ainsi que les R2 (notions définies précédemment).Le premier constat que nous pouvons d’ores et déjà faire à partir du tableau 52 est que les 8 modèles construits à partir des métriques COC, LOC et WMPC, prises comme variables explicatives, présentent une aire sous la courbe ROC (AUC) supérieure à 0,80, ce qui dénote de la précision et la performance significatives de ceux-ci. Les AUC des modèles construits à partir des données de JODA sont les plus élevées (nous avons respectivement pour l’effort de test et la couverture des tests: 0,983 et 0,930),
Par rapport à la qualité de la régression, que nous pouvons analyser à partir des valeurs du R2 de McFadden, il semble que les modèles de JO DA et 10 présentent les valeurs les plus élevées (entre 0,40 et 0,70), ce qui justifie les AUC élevées citées précédemment. Nous avons toutefois des valeurs du R2 moindres pour les modèles des systèmes JFREECHART et POL (pour l’effort de test nous avons respectivement 0,303 et 0,234 et pour la couverture des tests, 0,334 et 0,316).Par conséquent, à ce stade de notre analyse des modèles, un certain « pattern » des modèles se dessine avec d’une part des modèles plus précis et plus performants que sont ceux qui sont relatifs aux systèmes JODA et 10, et d’autre part, des modèles moins précis et moins performants, ceux qui sont relatifs à JFREECHAR T et POl
|
Table des matières
CHAPITRE 1. Introduction
1.1. Problématique
1.2. Approche
1.3. Organisation
CHAPITRE 2. État de l’art: bref aperçu
2.1. Métriques orientées-objet
2.1.1 Métriques de cohésion
2.1.2 Métriques de couplage
2.1.3 Métriques d’héritage
2.1.4 Métriques de taille
2.1.5 Métriques de complexité
2.2. Métriques de test
2.3. Méthodes d’expérimentation .
2.3.1 Corrélations
2.3.2 Régression logistique
2.3.3 K-Means
2.4. Outils d’expérimentation
2.4.1 Borland Together
2.4.2 XLSTAT
2.4.3 Weka
CHAPITRE 3. Catégorisation et Taux de couverture
3.1. Taux de couverture
3.1.1 Définition
3.1.2 Limitation
3.1.3 Re-calcul
3.2. Catégorisation des classes orientées-objet
CHAPITRE 4. Observation des métriques orientées-objet versus la couverture de tests
4.1. Objectif
4.2. Hypothèse
4.3. Systèmes logiciels
4.3.1 JFREECHART
4.3.2 JO DA
4.3.3 10
4.3.4 POl
4.4. Expérimentation
4.4.1 JFREECHART
4.4.2 JO DA
4.4.3 10
4.4.4 POl
CHAPITRE 5. Observation de l’effort de test versus la couverture de tests
5.1. Objectif
5.2. Hypothèse
5.3. Expérimentation
5.3.1 JFREECHART
5.3.2 JO DA
5.3.3 10
5.3.4 POl
CHAPITRE 6. Vers la priorisation des tests
6.1. Objectif.
6.2. Hypothèse
6.3. Démarche expérimentale
6.4. Expérimentation
6.4.1 Régression logistique
6.4.2 Interprétation des modèles
6.4.3 JFREECHART
6.4.4 JODA
6.4.5 10
6.4.6 POl
7 CHAPITRE 7. Conclusion
Bibliographie
![]() Télécharger le rapport complet
Télécharger le rapport complet