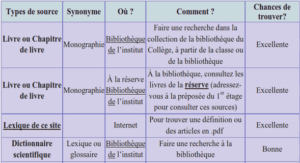
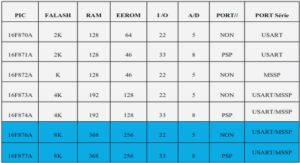
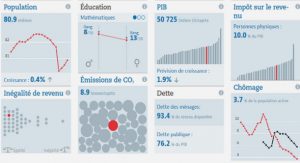
Télécharger le fichier pdf d’un mémoire de fin d’études
Capteurs extéroceptifs et proprioceptifs
Les informations issues de l’environnement servant à composer une carte et se localiser peuvent être acquises par une grande variété de capteurs. On distingue deux grandes familles de capteurs : les capteurs proprioceptifs et les capteurs extéroceptifs.
Un capteur extéroceptif permet d’évaluer une mesure par rapport à un point fixe de l’environnement (un amer avec des coordonnées métriques par exemple). Cette mesure, même si elle est entâchée d’erreurs (incertitudes), est absolue. Parmi les méthodes faisant usage d’informations extéroceptives en navigation robotique, on trouve la triangulation par GPS, ou encore l’estimation de position par rapport à des mires artificielles (comme des QRcodes présentés dans l’article [LL09]) dans un bâtiment. D’autres capteurs tels que les télémètres laser, radar, LIDAR peuvent être utilisés au cœur de méthodes analogues.
Un capteur proprioceptif mesure une information qui est relative, et le plus souvent propre à l’état antérieur du système. Il s’agit par exemple de la mesure du déplacement angulaire des roues du robot, permettant de reconstituer sa trajectoire. Il arrive souvent par contre que les roues glissent ou dérapent suivant la nature du terrain. Il s’ensuit une dérive dans l’estimation de la trajectoire qui s’accumule au cours du temps.
Les méthodes faisant appel aux capteurs proprioceptifs sont la plupart du temps plus précises. Elles sont sujettes à des erreurs et incertitudes plus faibles que pour des information extéroceptives. Néanmoins, la plupart du temps, on combine des informations proprioceptives, certe plus précises mais soumises à des dérives, avec des informations extéroceptives afin d’estimer et de compenser les dérives accumulées.
Un même capteur peut être utilisé à la fois pour des informations extéroceptives et proprioceptives. Si l’on prend l’exemple d’une caméra, reconnaître une mire visible et de taille connue dans le champ de la caméra permet destimer une position absolue de la caméra par rapport à cette mire. La même caméra pourra être utilisée pour estimer les poses entre deux de ses acquisitions successives : on parle alors d’odométrie visuelle. L’information ainsi acquise est proprioceptive. Nous reviendrons plus en détails dans la section 3.1.2 sur la technique d’odométrie visuelle.
La variété des environnements en robotique
Les contextes d’usage des robots font que les environnements parcourus peuvent être de type intérieur ou extérieur.
La navigation d’un robot en milieu intérieur s’exerce dans un contexte industriel (ex. : manutention dans un entrepôt) ou domestique (ex. : aide à la personne, robots compagnons et de divertissement). Ces environnements sont plutôt maîtrisés en terme d’éclairage constant et d’espaces navigables. Ils sont par contre source d’aliasing, c’est-à-dire que les perceptions que le système reçoit de son environnement pour plusieurs localisations peuvent être très proches voire identiques (les deux positions se confondent). Pour éviter cela, il est plus aisé d’augmenter l’environnement de repères uniques qui feront office d’amers.
La navigation d’un robot en milieu extérieur quant à elle s’exerce souvent dans des contextes exploratoires (robotique sous-marine, photographie aérienne) qui sont des situations difficilement accessibles à l’homme ou des situations très contraintes comme la navigation urbaine. Dans ce dernier cas, le système se trouve plongé au cœur d’un environnement difficilement prévisible. Le système est confronté à des éléments dynamiques à court-terme tels que les véhicules (voitures et camions) et autres usagers de la route (piétons et cyclistes) ou obstacles (animaux, végétation). Le système doit en outre être capable d’interagir avec des éléments artificiels issus de l’infrastructure routière (feux tricolores par exemple). D’autres éléments présentent des variations de l’environnement à long terme. Il s’agit des variations d’illumination de la scène perçue à différents moments de la journée et suivant des conditions météorologiques variables. Les saisons apportent également des changements d’apparence sur la végétion ou dégradent les conditions de visibilité (pluie, brouillard, neige).
Degré d’autonomie et véhicule (critères NHTSA et SIA)
Comme les systèmes d’aide à la conduite délèguent de plus en plus d’actions à la machine, la navigation d’un véhicule autonome s’apparente aux tâches et contraintes rencontrées en robotique. De plus, la navigation d’un véhicule sur une infrastructure routière est particulièrement critique. En effet, en plus d’être confronté à un environ-nement particulièrement dynamique et hétérogène, les vitesses des acteurs en jeu sont élevées et les distances de perception requises sont plus importantes. De ce fait, des conséquences dramatiques peuvent émerger d’une défaillance du véhicule. La conception et le fonctionnement de tels systèmes doivent donc être robustes et précis. Pour cela une législation et des codifications ont été définies par plusieurs institutions comme le NHTSA (National Highway Traffic Safety Administration) et la SIA (Société des ingénieurs de l’automobile) qui définissent 5 niveaux d’automatisation allant de la conduite sans automatisation (niveau 0) à un véhicule totalement autonome (niveau 4).
Extraction des informations : Primitives des images
«Quantification»/échantillonnage des informations de l’image
Une image brute est une quantité d’information importante en soi. La discipline de la vision par ordinateur s’attèle à définir le type d’information (critères photométriques, formes, contrastes, textures, etc) que l’on va extraire à l’aide de méthodes données et adaptées à l’application visée. On choisit ainsi des caractéristiques données, ou
Features features, que l’on va calculer plutôt que d’autres. Si l’on s’intéresse à une image dans sa globalité sans a priori sur la nature des objets ou de la scène observée, deux possibilités s’offrent à nous : la première est d’extraire les caractéristiques selon une «grille» fixe, la deuxième consiste à détecter des points d’intérêt comme nous le verrons dans la partie 1.3.1.
Méthodes fixes, arbitraires
La méthode la plus simple pour extraire de l’information d’une image dans sa globalité est de diviser l’image en zones arbitraires. Ces zones sont la plupart du temps des carrés de dimensions pixelliques identiques [SNP13, NSBS14] mais elles peuvent prendre d’autres formes dans le cas d’usage d’optiques fisheye ou omnidirectionnelle par exemple. Un exemple d’échantillonnage par grille est donné dans la figure 1.13.
Au cours des travaux de cette thèse, nous avons proposé une méthode de détermi-nation de la grille d’échantillonnage des features liée aux paramètres intrinsèques du capteur de façon à pouvoir comparer des features extraites d’images issues de capteurs aux caractéristiques différentes. Cette méthode est présentée dans la partie 2.1.
Extraction des informations : Primitives des images
Détection de points d’intérêt
On trouve dans la littérature deux termes distincts, feature detection et feature extraction , qui représentent selon les auteurs plus ou moins le même concept. Nous Feature choisissons ici de distinguer les deux en précisant que la méthode de détection réalise extraction la localisation de la caractéristique dans l’image (et détermine éventuellement sa taille, son orientation ou même sa forme dans le cas de détecteurs de blob que nous étudierons par la suite) alors que les méthodes dites d’extraction incluent aussi la phase de description de la caractéristique (c’est-à-dire l’information utile par la suite, la plupart du temps sous forme de vecteurs de scalaires ou de chaînes de bits).
Point d’intérêt, région d’intérêt ou caractéristique locale
Une caractéristique locale idéale serait un point au sens géométrique, c’est-à-dire avec une localisation précise et de taille nulle. Dans les faits, les images numériques sont une représentation discrète, une quantification de la lumière émise par l’environnement projetée sur le plan du capteur. L’unité spatiale la plus petite est ainsi le pixel et il est nécessaire de considérer un voisinage local de chaque pixel à analyser pour déterminer si la zone considérée relève d’une caractéristique de type point ou non. Dans certains cas, en particulier pour des tâches de calibration ou reconstruction 3D de l’environnement qui nécessitent des positions les plus précises possibles de points, un ou différents modèles de points (une fois quantifiés par le capteur image) sont ajustés afin d’inférer une position sub-pixellique de l’hypothétique point. On parle ainsi de point d’intérêt.
Néanmoins, la plupart des applications nécessitent par la suite d’associer, et donc comparer différents points d’intérêt émanant de plusieurs images. On considère donc une région d’intérêt autour du point établi pour laquelle nous calculerons une des-cription. En général, la région d’intérêt correspond au voisinage qui a été utilisé pour la phase de détection du point, mais ce n’est pas toujours le cas. De plus, afin d’obtenir une description autour de points d’intérêt invariante aux rotations, mais aussi aux transformations affines et projectives, cette région d’intérêt peut nécessiter ré-échantillonnage ou interpolation avant de procéder à l’étape de description (ces détails seront présentés par la suite).
Le terme caractéristique locale (local feature) fait ainsi référence à un point d’intérêt accompagné d’une région d’intérêt choisie dans son voisinage proche et sur laquelle nous calculons une description.
Propriétés d’une caractéristique locale idéale
On recense les propriétés suivantes nécessaires à des caractéristiques de bonne qualité [TM08] :
— Répétabilité : une caractéristique détectée dans une première image doit être dé-tectée dans une autre image malgré des changements de conditions d’observation de la scène (éclairage ou point de vue par exemple)
— Caractère discriminant : les motifs décrits par les caractéristiques locales doivent être suffisamment variables et distincts afin d’associer au mieux les caractéris-tiques d’une image à l’autre
— Localité : les caractéristiques doivent être le plus «local» possible, c’est-à-dire représenter un ensemble de pixels restreint afin de réduire les risques d’occlusion et faciliter les problématiques d’estimation de transformations géométriques entre deux images
— Quantité : un compromis concernant le nombre de caractéristiques extraites doit être établi. En effet, plus le nombre de caractéristiques extraites est grand, plus on a de chance de décrire un objet de petite taille dans l’image. Mais un grand nombre de caractéristiques peut également conduire à des redondances dans l’information extraite et une représentation de l’image dans sa globalité non optimale. L’application visée détermine la densité de caractéristiques à extraire. En outre, la densité de caractéristiques extraites n’est pas constante dans l’image : les zones de fort contraste auront une réponse plus forte à la détection alors que les zones faiblement texturées retourneront peu ou pas de points (typiquement un ciel dégagé pour une scène extérieure). Il peut ainsi être nécessaire de forcer une répartition équitable des points détectés dans toutes les zones de l’image pour en tirer une représentation à la fois compacte et complète.
— Précision : un point doit être détecté avec une localisation précise pour une utili-sation ultérieure (en particulier pour les tâches de calibration et reconstruction 3D de l’environnement). Il doit en être de même pour sa taille et forme lorsque le détecteur prend en compte ces propriétés.
— Performance : Pour bon nombre d’applications, le temps de calcul nécessaire à l’extraction des points d’intérêt de l’image est une propriété déterminante dans les choix techniques effectués.
Multimodalité et approches directes
Les approches directes font référence à l’usage des images dans leur globalité. la méthode décrite dans [CDM14] en est un exemple qui se focalise sur l’usage de l’infor-mation mutuelle pour effectuer des tâches de recalage d’images et de suivi (tracking). Dans [MB13], les auteurs utilisent une méthode de recalage d’images multimodales au cœur d’un processus de SLAM (Simultaneous Localisation And Mapping soit «Lo-calisation et Cartographie Simultanées»). L’article [MV12] propose également une approche multimodale liant images visibles et infrarouges thermiques et annoncent des performances intéressantes de jour comme de nuit. Neanmoins, ces deux dernières références font usage des deux gammes spectrales au même moment, c’est-à-dire que les travaux menés utilisent toujours le même ensemble de capteurs joints quelques soient les expériences. Notre approche est différente : nous avons en effet fait le choix de nous placer dans l’hypothèse où deux systèmes différents peuvent faire usage de mêmes données. Ainsi, un système doit pouvoir faire une première acquisition et un deuxième, dans une autre modalité, doit être en mesure de pouvoir associer ses données avec celles du premier.
Des caractérisques ponctuelles adaptées à la multimodalité
Des travaux menés sur la question de la multimodalité en robotique, ou du moins sur l’association d’images de scènes naturelles, ont vu le jour ces dernières années. Certaines études sur le sujet ont été menées par [RCAC+14] par exemple. D’autres proposent des modifications à apporter à des extracteurs de caractéristiques locales pour les rendre invariantes au changement de modalité ont été proposées [FBS11, MA13].
Proposition d’un descripteur global
La mémoire : création d’une carte visuelle
Une carte visuelle est créée à partir de données provenant d’une première expérience réalisée avec un véhicule instrumenté. Ce véhicule dispose d’un GPS différentiel permettant d’obtenir une précision de la position mesurée de l’ordre du centimètre. Il est également équipé d’une caméra montée vers l’avant du véhicule. Le récepteur GPS nous permet d’associer précisément chaque image avec la position du véhicule au même moment. Nous appelons cette séquence vidéo la mémoire. Cette mémoire peut être comparée à une carte métrique avec des positions distinctives (ou lieux) pour lesquelles nous avons une vue acquise. Nous extrayons de chaque image de la mémoire une signature d’image, c’est-à-dire une caractéristique distinctive de l’image entière. La façon dont nous extrayons les signatures d’images pour la mémoire et la séquence en ligne est exactement la même. Nous allons par la suite comparer les signatures de la mémoire avec les signatures des images acquises en direct.
Calcul des signatures d’image
Méthode d’échantillonnage des caractéristiques
Nous avons choisi de décrire et de comparer des images avec des descripteurs globaux regroupant les descriptions de patches locaux. Nous réduisons la résolution des images et les divisons selon une grille régulière. La taille des imagettes obtenue est d’environ trente pixels pour la plupart des images. Si nous associons différents types de capteurs, nous devons être sûrs que les données sur les patches concernent approximativement les mêmes informations du monde physique. Contrairement aux méthodes de l’état de l’art qui définissent une grille arbitraire, nous proposons ici d’utiliser une grille liée à la géométrie de l’optique de la caméra (ses paramètres intrinsèques).
Nous considérons le modèle du sténopé présenté dans la section 1.2.1 avec fu et fv les distances focales en termes de pixels pour les axes x et y, (u0; v0) les coordonnées du point principal en pixels, X = [x; y; z; 1]T les coordonnées homogènes d’un point 3D de l’environnement par rapport à la caméra et x~ sa projection dans le repère des coordonnées de l’image. Nous définissons alors une sphère centrée sur le centre optique du modèle sténopé comme schématisé dans figure 2.1. Nous nommons l’angle d’ouverture.
|
Table des matières
1 Robotique mobile et vision par ordinateur
1.1 Robotique mobile
1.1.1 De l’automate au robot
1.1.2 La variété des environnements en robotique
1.2 Vision par ordinateur
1.2.1 Généralités et modélisation d’un capteur optique
1.2.2 Traitements et amélioration des images issues du capteur
1.3 Extraction des informations : Primitives des images
1.3.1 «Quantification»/échantillonnage des informations de l’image
1.3.2 Propriétés d’une caractéristique locale idéale
1.3.3 Détection basée sur les valeurs d’intensité de l’image
1.3.4 Méthodes de description
1.4 La problématique de la multimodalité
2 Vision multimodale visible/infrarouge
2.1 Proposition d’un descripteur global
2.1.1 La mémoire : création d’une carte visuelle
2.1.2 Calcul des signatures d’image
2.1.3 Comparaison des signatures d’images
2.1.4 Résultats expérimentaux
2.1.5 Discussion
2.2 Analyse de détecteurs de points courants face à la multimodalité
2.2.1 Observations qualitatives
2.2.2 Critères de choix des paramètres pour envisager un réglage automatique
2.2.3 Tests préliminaires sur la répétabilité des détecteurs
2.3 Proposition d’un descripteur ponctuel : PHROG
2.3.1 Méthodologie
2.3.2 PHROG appliqué à la problématique de la localisation visuelle
2.3.3 Discussion
3 Localisation et cohérence temporelle
3.1 Cohérence temporelle des séquences d’images
3.1.1 Asservissement visuel
3.1.2 Odométrie, Structure From Motion et SLAM
3.1.3 Robot kidnapping et fermeture de boucle
3.2 Mise en place d’un cadre probabiliste
3.2.1 Probabilités et théorie Bayésienne
3.2.2 Simplification du processus en chaîne de Markov
3.2.3 Hypothèses supplémentaires et types de filtres
3.3 Implémentation de deux filtres probabilistes
3.3.1 Approche avec un filtre Bayésien discret
3.3.2 Filtre particulaire
3.3.3 Discussion
Télécharger le rapport complet