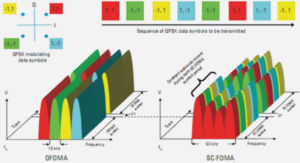
La modulation OFDM
Par rapport aux modulations monoporteuses, les modulations multiporteuses présentent l’avantage d’améliorer l’efficacité spectrale. Les premières études ([6] et [7]) sur les modulations multiporteuses ont vu le jour à la fin des années 50. Quelques années plus tard R.W. Chang et R.A. Gibby [8] introduisirent les signaux orthogonaux à bande limitée ce qui sera appelé « OFDM », . Ce moyen de transmission fut ignoré pendant de nombreuses années, pour des raisons de complexité de mise en oeuvre. L’usage d’algorithmes rapides de type (IFFT/FFT) ne sera proposé que plus tard [9], avec des réductions très significatives en complexité. Peled et Ruiz [10] proposeront une version modifiée (CP-OFDM) consistant à allonger la durée du symbole OFDM par l’insertion d’un intervalle de garde (cyclique). Grâce à ses bonnes performances et à sa complexité raisonnable, l’OFDM a été retenue dans plusieurs standards tels que les standards de diffusion numérique (DAB, DVB), les normes filaires (ADSL, PLC) et les réseaux locaux sans fil (WiFi, WiMax, etc). Le principe de l’OFDM consiste à diviser le flux binaire à haut débit en N sous-flux binaires bas débit, portés par Nsp sous-porteuses, ayant chacune une largeur de bande inférieure à la bande de cohérence du canal (figure 1.2). Sur chaque sous-porteuse, le canal peut être considéré comme non sélectif. La répartition des symboles sur (N = Nsp = NF F T ) sous-porteuses revient donc à multiplier la durée d’un symbole par Nsp, donc réduire le rapport (étalement du canal/durée symbole). Naturellement, certaines sous-porteuses seront fortement atténuées alors que d’autres le seront moins. Lors d’une transmission sur un canal à trajets multiples, la simple division de la bande passante en sous-bandes (OFDM) ne suffit pas à mitiger ces effets. Ainsi, une version modifiée de l’OFDM a été proposée. Elle consiste à attendre la fin de la transmission du k-ième symbole OFDM avant d’émettre le symbole suivant (k+1).
Les systèmes multi antennes : le principe du MIMO
Le principe de diversité a fait ses preuves d’augmentation de la robustesse et de la fiabilité des liens radio. Lorsque le récepteur reçoit plusieurs versions (aussi appelées branches) du signal émis, on parle de diversité. Sur un canal à évanouissements indépendants, la probabilité que les évanouissements arrivent en même temps devient nettement inférieure ce qui rend le lien plus robuste et plus fiable. Les évanouissements peuvent être dépendants du temps (sélectivité temporelle), de la fréquence (sélectivité fréquentielle) ou de l’espace ; il est alors possible d’utiliser la diversité d’une manière adaptée à chaque cas. Les diversités, temporelle (ajout de redondance par codage) et fréquentielle coûtent une perte en efficacité spectrale d’où l’intérêt de la diversité spatiale apportée par l’usage d’antennes multiples en émission et en réception. L’intérêt remarquable des systèmes MIMO réside dans le fait qu’il permet de réaliser des gains sans aucune ressource fréquentielle ou temporelle additionnelle ce qui signifie une meilleure exploitation du spectre. Jusqu’au début des années 90, l’usage d’antennes multiples était dans le but de l’exploitation du rapprochement des antennes afin d’adapter les diagrammes de rayonnement de l’ensemble (Smart Antennas) ainsi que pour l’estimation des angles d’arrivée des ondes. En émission ceci permet de concentrer la puissance dans la direction du récepteur. En réception ceci permet également de favoriser certaines directions d’arrivée et d’ignorer d’autres (rejet d’interférences). Quand l’espacement entre les antennes est suffisamment grand (typiquement supérieur à une demi-longueur d’onde), les différents canaux deviennent décorrélés et il est donc possible d’avoir des canaux parallèles et par la suite, d’augmenter le débit de transmission par multiplexage et de renforcer le rapport signal sur bruit. Dans [14], Winters montre la possibilité de créer des canaux parallèles en utilisant plusieurs antennes dans des configurations, mono et multi-utilisateur (en liaison descendante) et donne les premiers résultats sur la capacité. En 1995, E. Telatar montre que sous certaines conditions, la capacité des systèmes MIMO croît avec le minimum du nombre d’antennes d’émission et de réception [15]. Simultanément les Bell Labs présentent l’architecture appelée BLAST [16] qui permet d’obtenir des efficacités spectrales importantes avec un système de 8 antennes en émission et en réception. En 1998, les premières architectures de codage spatio-temporel apparaissent [17].
Le Multiplexage spatial
En 1996, G. Foschini introduit le premier schéma multiantennes réalisant du multiplexage spatial, qui permet la transmission d’autant de symboles différents que d’antennes en émission [16]. Le flux de bits d’information est divisé en Nt flux parallèles qui seront ensuite codés, puis entrelacés et modulés séparément. Les symboles sont transmis sur les antennes d’émission suivant une répartition diagonale qui confère au code son nom : diagonal-BLAST. La séparation des flux codés et la structure diagonale du multiplexage ajoutent une complexité considérable à l’émetteur. Woliansky [23] propose en 1998, un autre schéma, plus simple, connu sous le nom de Vertical-BLAST . Dans le schéma V-BLAST, la séparation des symboles en Nt flux n’a lieu qu’après le codage et la modulation. Aucun codage spatio-temporel n’étant effectué entre les symboles à l’émission, les techniques de multiplexage spatial ne bénéficient que de la diversité de réception. Afin de bénéficier de la diversité en émission, de la redondance peut être insérée à l’émission, on parle donc de codage espace-temps. L’ajout de redondance ne permet pas directement l’augmentation du débit, mais l’amélioration de la transmission par l’exploitation de la diversité. Le système pourra dans ce cas ainsi utiliser des modulations d’ordre plus élevé permettant ainsi une augmentation de l’efficacité spectrale atteignable à un rapport signal à bruit donné.
Détecteurs ML à complexité réduite – Le Sphere Decoding
Dans le but de préserver l’optimalité du critère ML, tout en réduisant la complexité, plusieurs solutions ont été proposées. En règle générale, elles consistent à limiter l’espace de recherche dans la détection. En d’autres mots, on ne considère que les vecteurs qui sont à l’intérieur d’une sphère construite autour du vecteur reçu, d’où le nom Sphere Decoding (SD). La recherche d’algorithmes de décodage par sphères repose sur deux critères : les performances doivent être le moins dégradées possible par rapport à la solution ML et le nombre de vecteurs testés doit être le plus petit possible. Le moyen le plus répandu d’effectuer le décodage par sphère consiste à représenter le problème sous la forme d’un arbre. À chaque branche de l’arbre est associée la composante réelle ou imaginaire d’un des symboles transmis. À chaque noeud de l’arbre, on vérifie que le vecteur testé est toujours contenu dans la sphère des solutions envisageables. Si oui, les branches associées à ce noeud sont étudiées, sinon ce candidat est abandonné. La première difficulté consiste à déterminer l’ordre de traitement des candidats. M. Pohst propose une stratégie de restriction des candidats utilisant une décomposition QR pour limiter les candidats à chaque étage de l’arbre de recherche [47]. Cette solution a ensuite été améliorée par C.P. Schnorr et M. Euchner en 1994 qui instaurent un ordre de traitement des candidats au niveau de chaque étage de l’arbre selon la distance par rapport à un point de référence. Le paramètre principal du décodage par sphère est le rayon de la sphère. Plus le rayon est grand, meilleures sont les performances, mais le nombre de candidats testés est plus important. À l’inverse, plus le rayon sera petit, moins il y aura de candidats testés engendrant une dégradation des performances. Par ailleurs, la complexité de la détection dépend également de l’ordonnancement de colonnes de la matrice H et du vecteur de référence à partir duquel l’énumération des candidats de Schnorr-Euchner est effectuée. On distingue principalement deux familles de décodage par sphère : les algorithmes de type depth-first-search ou breath-first-search. Dans le premier cas, il s’agit de minimiser le nombre de nœuds considérés en effectuant le traitement total d’une branche de treillis avant de traiter les autres. Dans ce cas, le nombre de candidats traités n’est pas constant et dépend du signal reçu et du rapport signal à bruit (moins il y a de bruit moins il y a de candidats traités). Afin de répondre à des critères d’implémentation, le second type d’algorithme traite un nombre limité de candidats à chaque étage du treillis puis considère l’étage suivant. Ainsi le nombre de candidats visités est constant au cours du temps. Les performances de ce type de détecteurs sont cependant moins bonnes à nombre de candidats traités équivalents. Bien que la solution ML soit optimale lorsqu’elle est considérée sans décodage de canal, ces détecteurs ne sont pas adaptés à l’utilisation de techniques de codage avancées dont le décodeur nécessite une information pondérée sur les bits. On utilise alors un détecteur à maximum a posteriori.
Turbo codes
En 1993, C. Berroux et al. [53], ont proposé un schéma de codage/décodage appelé « Turbo Codes ». Ce nouveau schéma est construit à partir d’une concaténation parallèle de deux codes convolutifs séparés par un entrelaceur afin d’assurer une certaine décorrélation entre les entrées des deux codeurs et assurer ainsi une meilleure diversité temporelle. Le principal intérêt des Turbo Codes n’est pas dans le schéma de codage, mais plutôt dans le schéma de décodage lequel introduit un échange itératif de l’information permettant d’exploiter au mieux la diversité temporelle. La figure (2.1) montre les schémas du Turbo codage/décodage. L’information souple entrelacée fournie par un décodeur est exploitée par le second comme information a priori. Ceci permet à l’ensemble de fournir au final des performances très proches de la limite de Shannon. Un grand intérêt a été raccordé aux turbocodes, on en cite les travaux de Benedetto et Montorsi [55], [56] et les travaux de Perez [57] qui ont permis de mieux comprendre le fonctionnement de ces codes. D’autres travaux ont permis d’étendre le décodage turbo des codes convolutifs aux codes en blocs [58], [59],[60]. Plus tard le principe turbo a été généralisé à l’ensemble de la chaîne de réception pour introduire la Turbo-égalisation, turbo-estimation et turbo-synchronisation changeant ainsi la manière dont on conçoit les récepteurs.
Évolution de densité – Profils de connexion
L’évolution de la densité (ED) [5] est une technique générique qui permet d’analyser les processus itératifs. Plus particulièrement l’ED permet de prédire les performances d’un code LDPC et donc de construire et optimiser la structure (les profils d’irrégularité) pour obtenir les meilleures performances. Dans le cas d’un mot de code de longueur infinie, le graphe LDPC peut être assimilé à un arbre. Le « théorème de la concentration », démontré par Richardson [80], montre que sous cette hypothèse, les performances des codes LDPC aléatoires convergent vers les performances moyennes. Les hypothèses de symétrie et de consistance des densités de probabilité des messages, permettent de simplifier le problème en se limitant à l’émission du mot (0, 0, . . . , 0). Sous ces hypothèses, la technique DE permet de définir un seuil de bruit au-dessous duquel la probabilité d’erreur tend vers zéro. La recherche de la structure optimale du code revient donc à rechercher les profils d’irrégularité qui permettent d’atteindre ce seuil. L’ED reste une méthode complexe vu le nombre important de combinaisons possibles.
|
Table des matières
Introduction
1 Les systèmes MIMO-OFDM
1.1 Avant-propos
1.2 Généralités
1.2.1 Canal de propagation
1.2.1.1 Bande de cohérence : définitions ajustées
1.2.1.2 Temps de cohérence
1.2.1.3 Canal de rayleigh
1.2.2 Égalisation
1.2.2.1 Détection à maximum de vraisemblance
1.2.2.2 Détection linéaire
1.2.3 La modulation OFDM
1.2.4 Les systèmes multi antennes : le principe du MIMO
1.2.5 Canal MIMO
1.2.6 Transmission MIMO
1.2.6.1 Le Multiplexage spatial
1.2.6.2 Le Codage spatio-temporel
1.2.6.3 Techniques MIMO avec connaissance du canal en émission et réception
1.2.6.4 Techniques MIMO sans connaissance du canal
1.2.7 MIMO-OFDM
1.3 Détecteurs MIMO
1.3.1 Détecteurs à maximum de vraisemblance
1.3.1.1 Détecteurs ML à complexité réduite – Le Sphere Decoding
1.3.2 Détecteurs à filtrage linéaire
1.3.3 Détecteurs à annulation d’interférence
1.4 Conclusion
2 Système MIMO itératif et codage LDPC
2.1 Introduction
2.2 Codage canal
2.2.1 Codes linéaires en bloc
2.2.2 Turbo codes
2.3 Les Codes LDPC
2.3.1 Les codes LDPC réguliers
2.3.2 Les codes LDPC irréguliers
2.3.3 Encodage LDPC
2.3.4 Décodage LDPC
2.3.4.1 Algorithmes de décodage dérivés
2.3.4.2 Ordonnancement du décodage LDPC
2.4 Construction et optimisation des codes LDPC
2.4.1 Évolution de densité – Profils de connexion
2.4.2 Les Diagrammes EXIT
2.4.3 Optimisation des codes LDPC par le diagramme EXIT
2.5 codes LDPC en Expansion
2.6 Les codes LDPC non binaires
2.7 Turbo-égalisation
2.7.1 Détection MIMO MMSE-IC
2.7.1.1 Solution exacte
2.7.1.2 Approximation MMSE-IC1
2.8 Conclusion
3 Ordonnancement statique du récepteur
3.1 Introduction
3.2 Contexte
3.3 Récepteur itérarif MMSE-IC LDPC
3.4 Entrelaceme
3.5 Complexité
3.5.1 Complexité LDPC
3.5.2 Complexité MMSE-IC
3.5.3 Application numérique
3.6 Ordonnancement du récepteur
3.7 Ordonnancement statique
3.7.1 Nombre d’itérations externes
3.7.2 Diagrammes EXIT du code LDPC
3.7.3 Ordonnancement proposé
3.8 Conclusion
4 Ordonnancement dynamique du récepteur
4.1 Introduction
4.2 Ordonnancement dynamique
4.3 Évolution de la fiabilité avec les itérations
4.4 Critères d’arrêt
4.4.1 Critère du premier maximum – FMMR
4.4.2 Critère de la fiabilité moyenne constante – CMR
4.4.3 Pondération de la fiabilité moyenne
4.4.3.1 Mean Reliability On Information bits – MRI
4.4.3.2 Weighted Mean Reliability – WMR
4.4.3.3 Weighted Penalized Mean Reliability – WPMR
4.5 Simulations
4.5.1 Première itération externe
4.5.2 Quatrième itération externe
4.5.3 Comparaison des ordonnancements
4.6 Conclusion
5 Le MIMO multi-utilisateur (Xuser MIMO)
5.1 Introduction
5.2 Accès Multiple par Division Spatiale ou MU-MIMO
5.2.1 Précodage et beamforming
5.3 Scénarios d’interférence
5.3.1 Retour d’information sur l’interférence
5.3.2 Annulation itérative de l’interférence entre utilisateurs
5.3.2.1 Schéma PIC-SIC
5.4 La connaissance des MCS des interféreurs
5.4.1 Classification de modulation
5.4.2 Classification du rendement de codage
5.5 Simulations
5.5.1 Cas 2×2
5.5.2 Cas 4 x 4
5.6 Effet du décodage LDPC sur les performances du récepteur multi-utilisateur
5.7 Conclusion
6 Conclusions et Perspectives
Glossaire
Notations
6.1 Notations mathématiques
6.2 Variables
A Calcul des vecteurs d’égalisation optimaux selon le critère MMSE
A.1 Minimum Mean Square Error
A.2 Égalisation linéaire
A.3 Minimum Mean Square Error – Interference Canceler
B Codes LDPC
B.1 Codes LDPC de Gallager
B.2 Density Evolution
B.3 Matrices de codes LDPC de la norme IEEE 802.11n
C Publications
Index
Bibliographie
![]() Télécharger le rapport complet
Télécharger le rapport complet