Architectures reconfigurables
Des circuits programmables au matériel reconfigurable Les architectures configurables font partie intégrante du paysage des circuits intégrés depuis la fin des années 1970 avec l’émergence de composants logiques programmables (PLDs) comme les PALs (Programmable Array Logic) et les GALs (Generic Array Logic). Ces composants proposent, à l’origine, des capacités de configuration plutôt primitives si on les compare à des puces modernes : ils sont constitués de portes logiques de base (NON, ET, OU) qui sont connectées électriquement via une phase de programmation pour réaliser la tâche désirée par le concepteur.
Architectures reconfigurables
Si l’on n’évoque alors pas encore le terme d’architecture reconfigurable à proprement parler, c’est parce que l’opération de programmation de ces composants n’était à leur début possible qu’une seule fois : on parle alors de circuit One-Time Programmable (OTP). La révolution apportée par les circuits effaçables par rayons ultraviolets (UVPROM), puis électriquement effaçables et programmables (EEPROM) a permis l’essor des composants reconfigurables, dont la fonction pouvait être changée à volonté, in situ.
L’évolution des technologies des circuits intégrés a par la suite permis aux constructeurs de proposer des composants beaucoup plus complexes, reposants non pas sur des éléments logiques fixes dont on programme l’interconnexion, mais sur des éléments logiques configurables à plus gros grain placés sur un réseau de routage : ce sont les composants logiques programmables complexes (CPLDs). Les CPLDs sont composés de macrocellules qui peuvent elles-mêmes être assimilées aux GALs cités précédemment. Un circuit typique peut contenir jusqu’à 10 000 de ces macrocellules, ouvrant la voie à des applications beaucoup plus complexes.
Les FPGAs
Xilinx a commercialisé ses premiers Field-Programmable Gate Arrays (FPGAs) en 1985, ils sont alors similaires par leur structure aux CPLDs mais leur composition interne en font rapidement des circuits de premier choix. En particulier, l’utilisation de cellules mémoires volatiles à base de RAM statique (SRAM) leur a permis de réduire la surface occupée par les éléments configurables (les transistors à grille flottante utilisés pour une cellule EEPROM occupant plus de surface qu’une cellule SRAM), et donc d’obtenir une meilleure intégration. La cellule logique à la base d’une architecture FPGA permet aussi une configuration plus fine de la fonction désirée, au travers de l’utilisation d’une table de correspondance à k entrées (k-LUT).
Le projet Européen FlexTiles
Le projet Européen FP7 FlexTiles, achevé en 2015, vise à produire une architecture 3-D multi cœurs hétérogène, adaptative et reconfigurable dynamiquement.
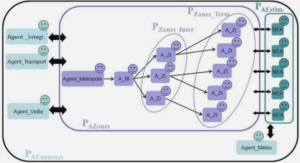
La Figure 0-10 illustre l’organisation générale de la plateforme FlexTiles. L’architecture s’organise autour du concept de tuiles, des éléments virtuels regroupant un processeur généraliste (GPP) et un ou plusieurs éléments hétérogènes de la plateforme parmi les processeurs de traitement du signal (DSP) et des tâches matérielles chargées sur la surface logique reconfigurable d’un FPGA embarqué, le eFPGA. Ces éléments communiquent entre eux par le biais d’un réseau sur puce (NoC) reliant à la fois les processeurs généralistes et les accélérateurs.
L’ensemble de la plateforme est gérée par une couche logicielle de virtualisation gérant la répartition des ressources au sein de l’application ainsi que la gestion globale de l’architecture.
eFPGA et le support de la reconfiguration matérielle à l’éxecution
Certaines innovations apportées par les travaux conduits dans le cadre de cette thèse ont été intégrées au sein de la plateforme FlexTiles, et notamment le concept de Virtual Bit-Streams. L’utilisation de cette représentation alternative des données de configuration d’une tâche matérielle est associée à l’intégration d’un contrôleur de reconfiguration intégré au circuit du eFPGA pour gérer le décodage des Virtual Bit-Streams. Ce contrôleur de reconfiguration intègre notamment les algorithmes de décodage décrits précédemment.
Les spécificités de cette architecture reconfigurable embarquée, en comparaison avec les architectures FPGA courantes du marché, sont nombreuses. Les communications entre les tâches matérielles chargées sur le eFPGA et le reste du système se font uniquement au travers d’interfaces normalisées communes à tous les accélérateurs de la plateforme FlexTiles. Ces interfaces, les AIs, sont couplées à une interface de communication avec le réseau sur puce, les NIs, eux-mêmes associés à des éléments physiques de communications entre les deux circuits superposés. L’ensemble forme un 3DNI, géré du point de vue de l’architecture FPGA comme un des éléments hétérogènes de la surface logique. Le reste de la surface logique intègre des RAM et des accélérateurs arithmétiques, ainsi que des éléments logiques formés de grappes de 6-LUT.
Pour déterminer l’agencement final des éléments sur la surface logique (leur nombre et leur taille relative), chacun d’entre eux a été développé en Verilog en intégrant les contraintes de reconfiguration et de la technique du Virtual Bit-Stream.
Le Tableau 0-2 résume les résultats en surface de la synthèse de ces éléments sur des technologies 65nm et 28nm de STMicroeletronics.
Simulation et validation de la surface reconfigurable
La simulation et la validation de l’ensemble du circuit eFPGA, comprenant le contrôleur de reconfiguration ainsi que le modèle Register Transfer Level (RTL) de l’architecture FPGA, a été réalisée en co-simulation Verilog et C. Pour des raisons de flexibilité de l’implémentation du contrôleur de reconfiguration, les spécifications de celui-ci ont été développées en C et intégrées au modèle RTL de la surface logique reconfigurable. Le contrôleur s’occupe ainsi de la lecture des flux de configuration, de leur décodage, puis du chargement des tâches dans la mémoire de configuration du modèle RTL.
Cette simulation a permis de valider les concepts introduits par ces travaux de thèse dans le cadre de la plateforme FlexTiles, à la fois au sens implémentation matérielle des méthodes décrites jusqu’ici, et aussi par le biais du flot de développement associé au Virtual Bit-Stream, lui aussi intégré à la suite d’outils utilisés par la plateforme FlexTiles.
Look-up tables
Look-Up Tables are nowadays the de facto finest versatile computing element in modern FPGA devices. A k-LUT is a small memory containing the truth table of a k-input logic equation. Figure 1-4a illustrates the abstract view of a k-LUT: the truth table itself is contained in a 2 k bits memory, and an address decoder is implemented with a multiplexer. The logic inputs are tied to the multiplexer control lines in order to select the truth table output for a given set of k inputs. A more detailed view of a k-LUT is shown in Figure 1-4b where the memory is implemented with SRAM cells and the decoder with pass-transistors, as mentioned in Section 2.
A major advantage of k-LUTs is their ability to implement any k input boolean equation. The inclusion of LUTs and interconnect in the architecture would be enough for a completely asynchronous programmable device, which is not the goal of FPGAs. The need to implement complex functions on the logic fabric make the inclusion of synchronization elements in the logic chain a requirement in FPGA architectures. The synchronization is brought aside the LUT s as an optional path for the logic. Figure 1-5 shows a simplified overview of what can be considered the basic logic block of an FPGA: the LUT is associated with a D flip-flop synchronized to the device clock. Using an additional multiplexer, it is possible for the basic logic block to either output a synchronized signal of the LUT output in order to have a stable logic value, or to bypass the flip-flop and chain multiple basic blocks to compute more complex equations in a single clock cycle. The maximum length of such a chain is limited by the length of the interconnect between each logic element and by the device clock speed.
Towards complex logic
As specified earlier, the design space of logic block elements has been explored in various direction since the early beginning of FPGA devices, each new architecture bringing its own advances. In most of the modern architectures such as the Xilinx Virtex 7 or the Altera Stratix V, the logic block is not anymore composed of a single LUT. Over the years, the effect of the LUT size (i.e. the number of inputs) and of the combination of multiple LUTs together in a logic cluster have been studied.
A clustered logic block comprises multiple basic logic blocks associated to a local crossbar network which interconnects the cluster inputs and the basic logic block outputs to the basic logic block inputs, as illustrated by Figure 1-6. Depending on the architecture, this local crossbar may be more or less complete in order to make a trade-off between the routing area and flexibility. The cluster is defined by its LUT size k, the number of LUTs N and the amount of inputs to the cluster I .
Routing
The routing process maps the interconnections between the various elements of the netlist to the routing resources available on the FPGA. In the case of an islandstyle architecture this is the set of routing channels and switch boxes to traverse to create the paths required for each net of the design.
The routing process problem resides in the finite set of routing resources available to route all the nets of the design. As the complete set of nets is routed on the fabric, some highly-congested parts will be deprived of available resources, while less used portions of the design will still offer many more available segments which can be considered as wasted. Unlike placement algorithms, the routing algorithm may fail when the pool of available routing resources is exhausted in certain locations of the design.
Given the regular topology of FPGA architectures, such as the island-style architecture, the routing step of the flow is really similar to the one performed on standard-cell ASIC design and Mask-Programmable Gate Arrays (MPGAs). Routing the netlist can be assimilated to a graph problem where the net endpoints are nodes of the graph (inputs, outputs, wire segments) and the programmable switches between them are the edges. Graph theory problems have been extensively researched since at least the work of Leonhard Euler in the XVIIIth century on the seven bridges of Königsberg. The basics of the FPGA routing problem are solved by maze routing algorithms [Lee61] which are generalizations of Dijkstra’s shortest path algorithm [Dij59].
The maze routing algorithm, detailed in Algorithm 1 finds the shortest path between two nodes in the routing graph. The first stage of the algorithm performs a wave propagation of incremental marks starting from the start node, until the end node gets marked, as demonstrated in Figure 2-4a. The second stage, shown in Figure 2-4b, backtracks the shortest path from the end node up to the start node. These operations are sequentially repeated for every net of the design. As each net will occupy resources in the graph, some of them will fail to be routed, and the routing process will have to rip up some selected nets to route them otherwise and allow more nets to be routed, iteratively.
Global architecture
The Flextiles architecture is based on a set of heterogeneous nodes among General Purpose Processors (GPPs), Digital Signal Processors (DSPs) or hardware accelerators loaded on an embedded FPGA, the eFPGA. A tile in the sense of the FlexTiles platform is an association between a master GPP node and one or more slave node.
Additionally, the platform features Double Data Rate (DDR) memory controllers and input/output elements. All these nodes are communicating together using a Network on Chip (NoC) backbone, as illustrated in Figure 7-2.
The communication homogeneity between the various nodes of the platform isensured by a Network Interface (NI) which provides the abstraction interface betweenthe nodes and the underlying NoC. Additionally, the data exchanges between the GPPs and their slave accelerator nodes are homogenized by Accelerator Interfaces (AIs), designed to implement the master/slave execution model.
Programming model
Applications targeting the Flextiles platform are defined as sets of static clusters. Each of these clusters is described using Synchronous Data Flow (SDF) or CycloStatic Data Flow (CSDF) computation models. Within the data-flows, the tokens consumers/producers are called actors. The actors communicate by exchanging tokens through First-In First-Outs (FIFOs) [NMG13].
The clusters of an application are independently designed and optimized using the platform dedicated tools. The design stage of a cluster is responsible for the partitioning, scheduling and mapping of its actors. A partitioning step groups closely related actors together in a partition. Each partition is then scheduled in a time scale, typically to manage an operator pipeline. Eventually , the clusters and their partitions are mapped to their final target tile on the platform.
Virtualization layer
A software virtualization layer is responsible for the architecture management ofthe available heterogeneous resources and for its adap tivity [Fer+12]. The system is systematically monitored to ensure that the application performance, the GPP and accelerator workloads, and the overall platform temperature stays within acceptable boundaries. A diagnostic phase allows taking various actions in function of the detected issues of the platform. It also draws conclusions regarding the actions to execute so as to counteract the problem. The actions include the decrease or increase of the processor frequency to meet the performance demand or power budget, the migration of a task if a GPP is overloaded, or triggering a defragmentation of the hardware resources to cope with the allocation of larger hardware tasks on the embedded FPGA logic fabric.
Additionally, each master GPP runs a custom operating system which locally handles the multi-threading of each processor as well as the scheduling and power management of the running clusters.
Embedded FPGA accelerators
A key point of the FlexTiles platform is to feature an embedded FPGA, the eFPGA, acting as a generic logic fabric on which dedicated accelerators (i.e. hardware tasks) are loaded at runtime to meet the performance needs of a data-flow application. Some of the runtime hardware reconfiguration features involved in the work of this thesis have been put to use in this context, to support the flexible runtime loading of hardware tasks.
|
Table des matières
Remerciements
Résumé
Abstract
0 Résumé étendu
1 Architectures reconfigurables
1.1 Des circuits programmables au matériel reconfigurable
1.2 Les FPGAs
1.3 Tâches matérielles : configuration du FPGA
2 Tâches matérielles relogeables
2.1 Abstraction des données de routage
2.2 Flot de conception amélioré
2.3 Intégration à l’architecture cible
3 Support matériel de l’hétérogénéité
3.1 Relogement entre régions hétérogènes
3.2 Architecture améliorée pour le relogement hétérogène
4 Organisation mémoire améliorée pour la configuration partielle
5 Le projet Européen FlexTiles
5.1 eFPGA et le support de la reconfiguration matérielle à l’éxecution
5.2 Simulation et validation de la surface reconfigurable
6 Contributions
7 Conclusion
Introduction
1 Context of the work
2 Contributions
3 Organization of the document
I Background
1 FPGA Architecture
1 (Re)configurable Hardware
1.1 Programmable Logic Devices
1.2 Reconfigurable devices
1.3 Advent of Field-Programmable Gate Arrays
2 Programming technology
2.1 Antifuse
2.2 Static memory
2.3 EEPROM / Flash
2.4 Summary
3 Logic array
3.1 Computing element
3.1-1 Logic blocks trade-offs
3.1-2 Look-up tables
3.1-3 Towards complex logic
3.2 Memory
3.3 Arithmetic accelerators
3.4 General purpose processors
3.5 Summary
4 Routing architecture
4.1 Segmented routing
4.1-1 Interconnect depletion
4.1-2 Segmented routing
4.2 Interconnect organization
4.2-1 Hierarchical architecture
4.2-2 Island-style architecture
4.3 Routing structure
4.3-1 Bi-directional routing
4.3-2 Unidirectional routing .
5 Conclusion
2 Runtime Reconfiguration and Routing of FPGAs
1 Runtime reconfiguration
1.1 Reconfigurability of Field-Programmable Gate Arrays (FPGAs)
1.2 Early work on runtime reconfiguration
1.3 Partial reconfiguration in modern devices
2 Task relocation/migration
2.1 Vendor-supported partial reconfiguration
2.2 On hacks of modern devices
2.2-1 Relocation on homogeneous fabric
2.2-2 Handling heterogeneous architectures
3 Run-time routing and communications
3.1 Bus macro
3.2 Configurable communication network
3.3 Bit-stream merging
3.4 Just-in-time routing
3.5 Conclusion
4 Placement and routing for FPGAs
4.1 High-level synthesis and non architecture-dependent optimizations
4.2 FPGA architecture mapping
4.3 Placement
4.4 Routing
4.4-1 Global and detailed routing
4.4-2 Combined routing
4.5 Verilog to Routing
4.5-1 VTR design flow
4.5-2 Applications to commercial FPGAs
5 Conclusion
II Contributions
3 Position-independent tasks: Virtual Bit-Streams
1 Motivation for position-independent bit-streams
2 Virtual Bit-Stream concept
2.1 Interconnect abstraction
2.2 Route modeling
2.3 Coding the Virtual Bit-Stream
2.3-1 Metadata
2.3-2 Macro-cells
2.3-3 Overview
3 Clustering
4 Virtual Bit-Stream generation tools
4.1 Design flow overview
4.1-1 Outputs of the Verilog-To-Routing flow
4.1-2 Virtual Bit-Stream generation
4.1-3 Decoding check
4.2 vbsgen, the Virtual Bit-Stream generation back-end
4.2-1 Architecture model framework
4.2-2 Model array
4.2-3 Output file generation
5 A Virtual Bit-Stream powered architecture
5.1 Reconfiguration controller
5.1-1 Pre-fetcher
5.1-2 De-virtualizer
5.1-3 Logic mapper
6 Limitations
4 Results and online decoding of the Virtual Bit-Stream
1 Introduction
1.1 Organization of the de-virtualizer
1.2 Real-time considerations
2 Online decoding algorithms
2.1 LUT-based decoder
2.2 State-machine decoder
2.3 Comparison
2.4 Implementation results
3 Compression effect of the Virtual Bit-Stream
3.1 Experimental methodology
3.2 Results
3.3 On the effect of clustering
3.4 Fallback coding: to the limits of the Virtual Bit-Stream
3.4-1 Analysis of the decoding failures
3.4-2 Experimental results
4 Conclusion
5 Architecture Enhancements
1 Task migration with heterogeneous blocks
1.1 Hard blocks abstraction
1.1-1 Routing network separation
1.2 Partitioning
1.3 Task model
2 Experimental methodology
2.1 Modeling in VPR
2.1-1 Architecture
2.1-2 Routing abstraction
2.2 Benchmarks
3 Results
3.1 Logic array size
3.2 Critical delay
3.3 Routing resources
3.3-1 Effect of the enhanced routing architecture
3.3-2 Limitations of the enhanced model within VPR
4 Conclusion
6 Enhancing the Virtual Bit-Stream Architecture
1 Introduction
1.1 Bit-stream loading methods
1.1-1 Word addressing
1.1-2 Scan-path: serial loading
1.1-3 Hybrid loading
1.2 Multi context configuration memory
1.3 Summary of memory organizations
2 Enhanced scan-path
2.1 Organization of the configuration memory
2.1-1 Configuration routing element
2.1-2 Configuration path
2.2 Runtime dynamic partitioning
2.2-1 Configuring the configuration path
2.2-2 Overhead and delay considerations
2.3 Results
2.3-1 Configuration time
2.3-2 Padding data overhead
2.3-3 Energy consumption
3 Conclusion
7 The FlexTiles platform
1 Overview of the FlexTiles project
1.1 Global architecture
1.2 Programming model
1.3 Virtualization layer
2 Embedded FPGA accelerators
2.1 Overview of the embedded FPGA
2.2 eFPGA architecture
2.3 Hardware tasks
3 Implementation of a dynamically reconfigurable FPGA
3.1 RTL model
3.1-1 Generation of the RTL model
3.2 eFPGA testbench
3.2-1 Testbench implementation
3.2-2 User interaction
4 Conclusion
Conclusion and Perspectives
1 Overview
2 Perspectives
III Appendices
A Hardware specifications of the eFPGA
1 Logic macro-cell
2 Logic blocks
2.1 Complex Logic Block
2.2 Arithmetic accelerator
2.3 Memory block
2.4 Accelerator interface
3 Logic fabric organization
3.1 Synthesis results
3.2 Proposed organization
B Simulation of the eFPGA reconfiguration controller
1 Task synthesis and bit-stream generation
2 Model configuration and shell connection
3 Adder loading
4 Adder test
5 Multiplier loading
6 Multiplier test
Publications 1
Bibliography
List of Figures
List of Tables
Acronyms