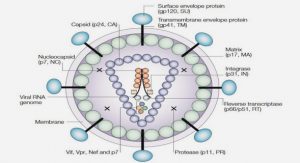
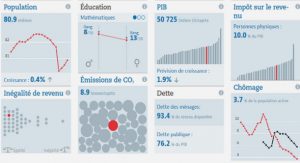
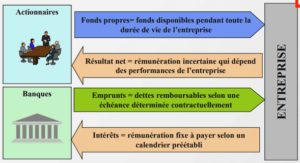
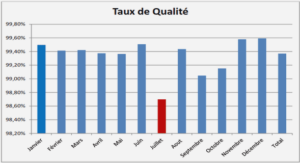
Télécharger le fichier pdf d’un mémoire de fin d’études
Méthode de Hurst [12]
Hurst a proposé le modèle suivant liant l’étendue R, l’écart type σ et l’exposant H1 pour caractériser le mémoire d’un processus. ?(?)?(?)=??1 (2.1)
Dans cette relation, la pente de la régression linéaire de ???(??) sur ??? ? constitue une bonne approximation de H1 avec : ?̅=1?Σ????=1 (2.2)
??=??−?̅ ? variant de 1 à ? (2.3).
??=Σ????=1 ? variant de 1 à ? (2.4).
?(?)=max(??)1≤?≤?−min(??)1≤?≤? (2.5).
?(?)=√1?Σ(??−?̅)2??=1 (2.6).
ou ? représente la taille de l’échantillon prise égale à N, N/2, N/4… et ? la taille de l’échantillon total.
Dans cette étude, pour trouver H1, nous avons conçus un petit programme sous Matlab.
Laboratoire Dynamique de l’Atmosphère, du Climat et des Océans 34
Selon Hurst, le mémoire d’un processus est fonction de la valeur de l’exposant H1.
Ainsi :
si la valeur de H1 est comprise entre 0,5 et 1 au sens strict, on dit que le processus est persistant ou à mémoire longue ;
si la valeur de H1 est comprise entre 0 et 0,5 au sens strict, on dit que le processus est anti-persistant ou à mémoire courte;
si H1 = 0,5 le processus n’a pas de mémoire.
La valeur du paramètre H1 donne une indication sur l’interdépendance des données. Par conséquent, elle nous informe sur la possibilité de modélisation du processus par la méthode ARIMA.
Par exemple, on modélise généralement les processus à mémoire longue par des modèles FARIMA (ARMA intégré avec un ordre fractionnaire) [13], mais cela n’exclut pas la possibilité de modélisation par des modèles ARIMA
Méthode statistique de préparation et d’analyse des données
Courbe représentative des données initiales
Elle permet de visualiser l’allure générale de la courbe et de détecter s’il existe une tendance, une saisonnalité ou une rupture au niveau des observations [14]. Pour faire apparaitre cette courbe sous Matlab 2013a, nous avons utilisé la fonction « Plot (x) ».
Préparation des données
Avant tout analyse, il est important de s’assurer de la fiabilité des données, d’une part, il faut confirmer l’homogénéité des données et d’autre part, il faut détecter les points atypiques, les corriger et si nécessaire les supprimer.
Vérification de l’homogénéité des données
On peut vérifier l’homogénéité des données en construisant l’histogramme, si les données sont homogènes, nous observerons un seul mode et si la chronique est hétérogène, nous obtenons un histogramme multimodal [15].
Pour construire l’histogramme, nous avons utilisé la règle de STURGES [16].
Elle permet en premier lieu de calculer le nombre de classes k2 en utilisant la relation ?2=1+3,322 ???10(?) (2.7).
Méthode spectrale de détection et de calcul de la périodicité S
Plusieurs méthodes existent pour déterminer la valeur de la saisonnalité S. L’approche retenue consiste à construire pour chaque chronique, la courbe de la densité spectrale en fonction de la période (ou fréquence).
Notre problème se ramène donc :
à l’estimation de la Densité Spectrale de Puissance (DSP),
et au calcul de la fréquence ou période correspondante.
Laboratoire Dynamique de l’Atmosphère, du Climat et des Océans 38
Estimation de la DSP
La densité spectrale contient la même information que la fonction d’autocovariance dans le domaine fréquentiel. En particulier, elle permet d’identifier la tendance, les saisonnalité, les cycles .
Pour trouver la DSP, nous avons décidé d’appliquer avec une fonction d’apodisation rectangulaire :
la méthode du corrélogramme ou méthode de BLACKMAN-TUCKEY ;
et la méthode du périodogramme qui se subdivise en deux catégories :
la méthode du périodogramme moyenné ;
la méthode du périodogramme par maximisation de l’entropie.
Méthode indirecte, méthode du corrélogramme ou méthode de BLACKMAN-TUCKEY [18]
Cette méthode consiste à estimer la densité spectrale comme la Transformée de Fourrier de la fonction de corrélation ??? : ???(?)=fft [?̂??(?3)] (2.15).
?̂??(?3)=1?−?3 Σ??+?3??∗?−?3−1?=0 (2.16).
fft (?3)=??Σ???−2??(?−1)×(?3−1)???=1 [19] [20] (2.17).
où on a fft la Transformé de Fourier Rapide .
DSP la Densité Spectrale de Puissance .
? le nombre de points temporels .
? la variable temporelle variant de 1 à N .
?? les données périodique de période t .
? le nombre de points fréquentiels .
?3 la variable fréquentielle variant de 1 à L .
?̂?? l’éstimateur de la fonction d’autocorrélation ??? .
?? la période d’échantillonnage .
et ?? la fréquence d’échantillonnage.
Réduction du domaine d’étude
La parité de la fonction ???(?) (les xt sont des réels positifs), le théorème de Nyquist-Shannon qui stipule que la fréquence ?? d’échantillonnage doit être au moins égale au double de la fréquence maximale du signal à reproduire [25] et le mode d’itération sous Matlab (itérations à partir de 1 et non de 0), nous ont conduit à adopter le domaine fréquentiel ?=?????????2×[1 ,?2]=??2?2×[1 ,?2] (2.31).
Saisonnalité S en terme journalier
Notons que la saisonnalité S trouvée par les trois méthodes précédentes correspond à la saisonnalité liée aux rangs des temps de prélèvement.
Pour convertir cette saisonnalité en terme journalier, nous devons calculer la moyenne arithmétique en considérant comme variable la différence en jour entre deux temps de prélèvement successif sur les pleines mers ou sur les basses mers.
Pour ramener 1 Lag, sur les figures, en terme journalier, il suffit d’appliquer la relation d’équivalence
1 Lag=ΣDiNi=1N (jours) (2.32).
Après conversion, nous pourrons comparer la valeur des saisonnalités journalière S obtenus par nos méthodes de calcul avec celles fournies par les modèles de Newton ou de Laplace en utilisant le « test t de Student » (test d’égalité de la moyenne d’une série à une valeur donnée) défini au point c) du paragraphe 2.4.2.4.
Choix de la périodicité S
Comme la méthode du corrélogramme et celle du périodogramme donnent en général des valeurs non entières, il nous faut chercher leurs meilleures estimations sous la forme entière E(S) ou E(S+1) pour pouvoir mettre en oeuvre la méthode Census X-11.
Pour reconnaitre la meilleure estimation de la saisonnalité S, nous pouvons effectuer:
le test sur les résidus ;
l’analyse de la variance à un facteur.
Test sur les résidus [26]
Cette méthode consiste à choisir l’estimation de la saisonnalité S créant moins de fluctuation résiduelle (propriété des moyennes mobiles).
Analyse de la Variance à un facteur ou test de Fisher
Cette technique est utilisée pour des données indépendantes, homoscedastes et possédant une distribution normale ou approximativement normale [27][28].
Comme au paragraphe précèdent, on choisira toujours la période qui offre une meilleure transformation des données, c’est-à-dire, celle qui assure une meilleure stabilité saisonnière. L’indépendance des données découle de l’indépendance des moments de prélèvement des échantillons.
Pour tester la normalité, nous avons utilisé le test de Jarque et Bera et deux autres tests basés sur le coefficient d’aplatissement et le coefficient d’asymétrie [29]. La distribution de la variable ?(?) est normale si ?? =?6??2+?24??2≤5,99 (2.33).
ou si |??| = √?6.?? ≤1,96 (2.34).
Méthode de détection de la tendance
En pratique, les conditions d’application des tests paramétriques (indépendance, normalité, homoscédasticité) sont souvent difficiles à respecter.
Nous avons donc préféré nous orienter vers l’utilisation des tests non paramétriques pour déterminer l’existence de tendance au niveau de nos chroniques.
Pour étudier la corrélation entre les rangs de la hauteur des pleines mers ou des basses mers noté ?? et les rangs de leurs temps de prélèvement noté ??, nous avons mis en oeuvre les tests de corrélation de rang de Mann et de Kendall et le test de corrélation de rang de Spearman.
L’objectif de ces tests est de constater la significativité de la composante tendancielle dans le schéma de prévision.
Les tests de corrélation de rang de Mann et de Kendall [32] [33]
Pour étudier la corrélation entre deux grandeurs X et Y, Mann (1945) et Kendall (1970) [32] [33] proposaient d’effectuer des tests basés sur l’utilisation du :
coefficient de corrélation de rang ? ;
terme S’’.
Test basé sur l’utilisation du coefficient de corrélation de rang ? (Test de Kendall)
Dans son article « Rank Correlation Methods » en 1975, Kendall définissait le coefficient ?? par la relation ??=2?′′?(?−1) (2.49).
Méthode du profil
Elle consiste à superposer sur un même graphique, les courbes représentatives du profil dans chaque période. Si les courbes sont parallèles entre elles, nous choisissons un schéma additif et si elles s’entrecroisent alors nous optons pour un schéma multiplicatif.
Méthode de la bande
La méthode de la bande consiste à construire pour chaque période, d’une part la courbe des minima, et d’autre part la courbe des maxima. On adopte les deux règles de décisions suivantes :
Si les deux courbes sont parallèles, on opte pour le schéma multiplicatif,
Si les deux courbes s’entrecroisent, on choisit un schéma additif.
Méthode analytique
La méthode analytique consiste à régresser pour chaque période l’écart type ?? par rapport à la moyenne ??̅.
Si la pente de la droite de régression ??=??̅?+?1 est significativement nulle alors nous adoptons un modèle additif avec saisonnalité rigide en amplitude et en période et si la pente de cette même droite est significativement non nulle, alors nous optons pour le choix d’un modèle multiplicatif. La saisonnalité est dans ce cas souple avec variation de l’amplitude au cours du temps.
Règles de décision.
Sous l’hypothèse Ho défini par « le coefficient n’est pas significativement différent de 0 » :
Si t-statistic < t-student de la table, alors on accepte Ho.
Si t-statistic > t-student de la table, alors on rejette Ho.
Les différents types de modèles
Modèle Census X11 [38]
La méthode Census X11 est une technique de dessaisonalisation des séries chronologiques par moyenne mobile centrée et pondérée.
Cette méthode utilise les moyennes mobiles de Henderson pour l’estimation de la tendance.
Pour sa mise en oeuvre, nous devons utiliser l’un des schémas de prévision que nous avons défini au paragraphe 2.3.5.
Quelque soit le schéma choisi, additif ou multiplicatif, cette méthode utilise la forme matricielle M1 des données que nous avons définie à la figure 2.2 et permet de séparer la composante saisonnière, des composantes tendancielle et résiduelle.
Pour trouver ces composantes, nous devons exécuter successivement les opérations suivantes.
Estimation de la Tendance tt,1 par moyenne mobile centrée d’ordre S [36]
La Tendance extra-saisonnière s’obtient en appliquant aux données brutes stabilisées une moyenne mobile centrée d’ordre S.
Cette moyenne mobile se calcule en utilisant pour une saisonnalité paire S la relation ??,1=12??(12??−??+??−??+1+⋯+??+??−1+12??+??)=?2??(??) (2.62) et pour une saisonnalité S impaire la formule ??,1=12??+1(??−??+??−??+1+ +??+??−1+??+??=?2??+1(??) (2.63) où ?? est un entier positif.
Estimation de la série corrigée des variations saisonnières scvst,1 [38]
Pour obtenir la série corrigée des variations saisonnières ?????,1 , on utilise la relation : ?????,1=??,1−??,1 (2.66).
Identification de d et p
Nous avons adopté la formulation de l’équation 2.3.72 proposée par Box et Jenkins [39] pour éliminer la tendance et stationnariser notre série en remplaçant les valeurs de ?? par celles de la série corrigée des variations saisonnière ?????,2
En pratique, nous pouvons retrouver l’ordre d’intégration « d » et l’ordre de la partie Autorégressive « p » qui optimise le modèle DFA en effectuant les trois étapes suivantes :
Minimisation de l’écart type en fonction de « d »
Application de la stratégie de Dickey Fuller Augmenté
Recherche de l’ordre d’intégration final « dfinal » et de l’ordre optimal « poptimal » du modèle DFA.
Minimisation de l’écart type de la série différenciée [39]
Cette méthode consiste à rechercher la valeur de « d » minimisant l’écart type de la série différenciée en faisant varier l’ordre d’intégration « d entre 0 et 2 et rarement entre 0 et 3 ».
Stratégie de Dickey Fuller Augmenté
Cette approche permet de retrouver, d’une part, l’ordre d’intégration « d » et d’autre part, de fixer le nombre de retard « pinitial » du modèle DFA.
Le principe est simple, on fixe tout d’abord un nombre de retard initial « p = pinitial », puis on effectue le test de stationnarité au sens de Dickey Fuller Augmenté en faisant varier l’ordre d’intégration « d » entre « dmin et dmin +1 ».
« dmin » représente la valeur de « d » minimisant l’écart type des séries différenciées.
Si le test de Dickey Fuller Augmenté confirme la stationnarité de la série différenciée et que les résidus sont non corrélés au test de Ljung-Box, alors :
le « d » choisi (dmin ou dmin +1) correspond au bon ordre d’intégration.
le nombre de retard « pinitial » choisi correspond à un ordre maximal acceptable pour notre modèle DFA.
Si le test de stationnarité de Dickey Fuller Augmenté est rejeté ou le test de Ljung Box sur les résidus n’est pas significative, alors le nombre de retard choisi n’est pas suffisant ; nous augmentons « pinitial » d’une ou de plusieurs unités et on refait les tests qui cette fois-ci devront confirmer la stationnarité au sens de Dickey Fuller Augmenté et au sens de Ljung-Box. Cette nouvelle valeur de « pinitial » représentera alors l’ordre maximal acceptable pour notre modèle DFA.
Le test de Dickey Fuller Augmenté que nous avons utilisé consiste à appliquer une stratégie [40] à travers le modèle 1, 2 et 3 définis respectivement par ??′=Ф ?′?−1+ΣФ? Δ?′?−???=1+?? (2.75)
|
Table des matières
1. Introduction générale
Chapitre 1. Généralités sur la mécanique
1.1. Introduction
1.2. La mécanique
1.2.1. Les référentiels de travail
1.2.1.1. Référentiel [6]
1.2.1.2. Référentiel de Copernic [6]
1.2.1.3. Référentiel géocentrique RG [6]
1.2.1.4. Référentiel terrestre RT [6]
1.2.2. Loi fondamentale en mécanique terrestre [7]
1.2.2.1. Bilan des forces appliquées [9]
1.2.2.2. Loi d’attraction Universelle [1]
1.2.2.3. Loi fondamentale de la mécanique terresre
1.2.3. Conclusion
1.3. Les théories des marées depuis Isaac Newton jusqu’à Doodson
1.3.1. Modèle de Newton [3] [9]
1.3.2. Interprétation du modèle de Newton
1.3.2.1. Cas ou le mouvement de rotation de la Terre sur elle-même est prépondérante
1.3.2.2. Cas ou le mouvement de translation circulaire de la Lune autour de la Terre est prépondérante
1.3.2.3. Cas ou le mouvement de translation circulaire de la Terre autour du Soleil est prépondérante
1.3.3. Cas ou la déclinaison δ est différent de zéro [3]
1.3.4. Modèle harmonique
1.3.4.1. Potentiel générateur des marées [11]
1.3.4.2. Développement en espèce de Laplace [3]
1.3.5. Conclusion
Chapitre 2. Matériels et méthodes
2.1. Introduction
2.2. Matériels
2.3. Méthodes
Laboratoire Dynamique de l’Atmosphère, du Climat et des Océans iv
2.3.1. Méthode de Hurst [12]
2.3.2. Méthode statistique de préparation et d’analyse des données
2.3.2.1. Courbe représentative des données initiales
2.3.2.2. Préparation des données
2.3.3. Méthode spectrale de détection et de calcul de la périodicité S
2.3.3.1. Estimation de la DSP
2.3.3.2. Formulation de la fréquence f et de la période S [20]
2.3.3.3. Réduction du domaine d’étude
2.3.3.4. Saisonnalité S en terme journalier
2.3.3.5. Choix de la périodicité S
2.3.4. Méthode de détection de la tendance
2.3.4.1. Les tests de corrélation de rang de Mann et de Kendall [32] [33]
2.3.4.2. Le test de corrélation sur les rangs de Spearman
2.3.5. Méthode d’identification du schéma de prévision [36]
2.3.5.1. Méthode du profil
2.3.5.2. Méthode de la bande
2.3.5.3. Méthode analytique
2.3.6. Conclusion
2.4. Les différents types de modèles
2.4.1. Modèle Census X11 [38]
2.4.1.1. Estimation de la Tendance tt,1 par moyenne mobile centrée d’ordre S [36]
2.4.1.2. Estimation de la composante saisonnière – irrégulière st,1 + rt,1 [38]
2.4.1.3. Estimation de la série corrigée des variations saisonnières scvst,1 [38]
2.4.1.4. Estimation de la tendance-cycle tt,2 par moyenne de Henderson à 13 ou 9 termes [38]
2.4.1.5. Nouvelle expression de la composante saisonnière-irrégulière st,2 + rt,2 [38]
2.4.1.6. Nouvelle expression de la série corrigée des variations saisonnière scvst,2 [38]
2.4.2. Modèle ARIMA (p+1,d,q) – GARCH (P,Q)
2.4.2.1. Identification de d et p
2.4.2.2. Identification de qinitial
2.4.2.3. Choix du modèle ARIMA(p+1,d,q)
2.4.2.4. Analyse des Résidus
2.4.2.5. Analyse de la qualité de la prévision
2.4.2.6. Analyse de la stabilité du modèle
2.4.3. Conclusion
Chapitre 3. Résultats et discussions : applications numériques au cas des marées de Hell-Ville
3.1. Introduction
3.2. Résultats et discussions
3.2.1. Sources des données
3.2.2. Localisation su site
3.2.3. Exposant de Hurst H1
3.2.4. Représentation graphique des données initiales
3.2.5. Histogramme
3.2.6. Préparation des données homogénéisées
3.2.7. Estimation de la saisonnalité S
3.2.7.1. Estimation de la saisonnalité S par corrélogramme ou la méthode de BLACKMAN-TUCKEY
3.2.7.2. Estimation de la saisonnalité S par périodogramme moyenné
3.2.7.3. Estimation de la saisonnalité par périodogramme par la Méthode de l’Entropie Maximale
3.2.8. Saisonnalité S en terme journalier
3.2.9. Choix de la Saisonnalité S
3.2.9.1. Test sur les Résidus
3.2.9.2. Analyse de la Variance à un Facteur
3.2.10. Analyse de la tendance sur les données stabilisées
3.2.10.1. Test de corrélation de rang de Kendall
3.2.10.2. Test de corrélation de rang de Mann-Kendall
3.2.10.3. Test de corrélation de rang de Spearman
3.2.11. Schéma de prévision
3.2.11.1. Méthode du profil
3.2.11.2. Méthode de la bande
3.2.11.3. Méthode analytique
3.2.12. Méthode Census X11
3.2.13. Méthode ARIMA(p+1,d,q)
3.2.13.1. Identification des ordres d, q et p du modèle ARIMA(p+1,d,q)
3.2.13.2. Identification de qmax
3.2.13.3. Choix du modèle ARIMA(p+1,d,q)
3.2.13.4. Analyse des résidus
3.2.13.5. Choix du modèle ARIMA(p+1,1,q)-GARCH(P,Q)
3.2.13.6. Analyse de la qualité de la prévision
3.2.14. Conclusion
Conclusion générale
Avantages et perspectives
Références bibliographiques
LISTE DE PUBLICATIONS
Télécharger le rapport complet