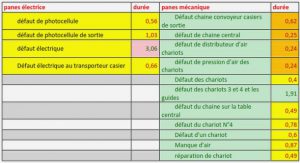
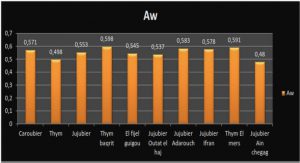
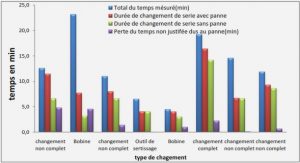
Télécharger le fichier pdf d’un mémoire de fin d’études
Caractéristiques et utilisation des documents d’archives
Comme mentionné dans l’introduction, notre travail s’est basé sur l’étude de fonds do-cumentaires particuliers (des registres de ventes du XVIIIe siècle) afin de permettre une validation pratique de nos propositions, avant de pouvoir espérer les généraliser. Nous in-troduisons ici quelques notions et éléments de vocabulaire généraux à propos des documents d’archives.
Typologie documentaire
La commission de normalisation « Modélisation, production et accès aux documents » de l’Association française de normalisation (AFNOR) [2] propose de définir les fonds d’ar-chives comme :
l’ensemble des documents de toute nature qu’une personne physique ou mo-rale, appelée le producteur, a produits ou reçus dans l’exercice de ses activi-tés, rassemblés de façon organique et conservés en vue d’une utilisation éven-tuelle. »
Le groupe de travail propose des distinguer les types de documents suivants, pouvant former tout ou une partie d’un fonds documentaire :
Manuscrits littéraires, manuscrits d’œuvre Tous les manuscrits d’une œuvre qu’elle soit littéraire ou non, publiée ou inédite.
Correspondance Lettres envoyées ou reçues par le producteur.
Archives relatives aux activités et à la vie d’une personne Documents résultants de l’ac-tivité professionnelle ou publique du producteur, comme des notes de travail ou des discours, ainsi que ceux relevant de sa vie privée, tels qu’un agenda, ou un testament.
Archives relatives à l’organisation et aux activités d’une collectivité Ensemble des do-cuments relatifs au fonctionnement d’une collectivité, à savoir les archives juridiques, administratives, comptables et financières, techniques et scientifiques, domaniales, ainsi que la documentation et les éventuels documents relatifs à toutes autre forme d’activité.
Dans le cadre du projet qui a servi de support à notre travail de recherche, c’est cette catégorie qui nous intéresse le plus.
Collections Pièces réunies dans un but précis par un collectionneur : autographes, manus-crits, etc.
Notons que le terme « collection » peut également être employé pour désigner un ensemble de documents organisés selon une thématique précise, et être alors synonyme de « fonds d’archives », et nous nous efforcerons d’éviter cette confusion en parlant de « fonds d’ar-chives », ou, plus généralement, de « fonds documentaires ».
Organisation documentaire
Classer pour faciliter l’accès
La commission insiste sur l’importance de l’organisation documentaire, afin de per-mettre l’organisation hiérarchique de fonds documentaires occupant jusqu’à plusieurs plu-sieurs centaines de mètres de stockage.
L’organisation des documents d’un fonds peut alors se faire selon plusieurs plans de classement, afin de décomposer progressivement la structure du fonds jusqu’à un niveau de détail satisfaisant ; la pièce, si nécessaire. Parmi ces plans, on peut trouver une organisa-tion typologique, souvent utilisée en premier niveau, une organisation thématique, souvent utilisée pour décomposer les fonds liés à des activités, et finalement une organisation chro-nologique, souvent terminale.
Au niveau numérique, les archivistes veillent à maintenir ce classement après la numé-risation des documents. Les images des différentes pages des documents obéissent alors à une organisation séquentielle cohérente, généralement regroupées par livre ou pièce au sein d’une structuration hiérarchique reproduisant la partie de la structure globale de laquelle le lot de documents numérisés a été extrait. Le nommage des fichiers numériques joue égale-ment un rôle important.
Exemple d’organisation :
série 1Q des archives départementales des Yvelines titre d’exemple, on présente rapidement le contenu de la série 1Q des archives dépar-tementales des Yvelines avec laquelle nous avons pu construire et valider notre approche. Ces documents seront utilisés abondamment dans cette thèse, à titre d’exemple. Aussi est-il pratique de les présenter dès à présent.
Par convention nationale, la série Q regroupe les documents relatifs à la vente des biens nationaux et des domaines de l’État (principalement) pendant la période suivant la Révolu-tion française, entre 1791 et 1800. Chaque département possède donc un fragment de cette série, et la numérotation présentée ci-après correspond à celle des archives départementales des Yvelines. La série 1Q regroupe, quant à elle, le sous-ensemble des documents relatifs aux actes de ventes. Dans le cas des fonds documentaires des archives départementales des Yvelines, on peut distinguer deux types de documents particulièrement intéressants dans ce fonds.
– 11 registres correspondant à 11 types de ventes, et répartis dans 329 sous-séries (cotes 1Q1 à 1Q329) correspondant à autant de livres physiques. Chacune des pages de ces registres contient une partie d’un tableau global regroupant les informations synthé-tiques relatives à chaque transaction : numéro, date, localisation du bien (commune), ancien propriétaire, nouvel acquéreur, etc.
Un extrait de page est visible en figure 1.1.
– Une table des communes (cote 1Q365) qui liste, par ordre alphabétique des com-munes, tous les numéros des bien situés sur une commune, classés par type de vente. Cette table propose donc un index des ventes.
Un extrait de page est visible en figure 1.2.
Nous avons pu disposer des images des pages des livres, classées par répertoire (1Q1, 1Q2, etc.), numérotées dans leur ordre de lecture. Cette organisation est représentative des don-nées dont un peut disposer lors d’une telle tâche, et montre déjà l’importance des liens entre les différentes parties d’un corpus documentaire.
Utilisation dématérialisée de fonds d’archives
Assister le lecteur
Le principal risque dans la dématérialisation de documents est de priver le lecteur, c’est dire l’utilisateur final du système de consultation des documents sous forme numérique, des facilités offertes par le papier. Baird [5] indique à cet effet quatre propriétés des docu-ments sous forme papier, qu’il semble nécessaire de reproduire dans la mise en place d’une consultation dématérialisée afin de permettre une utilisation pratique et confortable :
– le papier permet une navigation flexible entre les documents ;
– le papier facilite la consultation simultanée de plusieurs documents se référençant mutuellement ;
– le papier invite à l’annotation ;
– le papier permet l’enchevêtrement de la lecture et de l’écriture.
Faure et Vincent [38] proposent alors de centrer la conception des systèmes de consul-tation sur l’objectif d’assister le lecteur dans sa réappropriation du contenu des documents. Ce processus de réappropriation est alors organisé selon les quatre tâches fondamentales suivantes :
le traitement qui consiste à distinguer les signes (le contenu) du support (le fond) et saisir l’organisation des composants visuels de la page, afin de décoder le message contenu ;
la collecte qui consiste à regrouper les contenus selon des critères variés (thématiques, vi-suels) afin de les comparer, les retrouver, etc. ;
l’augmentation qui consiste associer des informations et des résultats de raisonnements à des contenus, c’est à dire à des parties des images des documents ;
la restructuration qui consiste à organiser l’information d’une façon différente de l’ordre de lecture original.
Assister le lecteur dans de telles opérations nécessite l’extraction d’informations riches, et la construction de structures de données adaptées à ces usages.
Transcrire et organiser
Faciliter la lecture peut être fait en proposant un nouveau formatage du document, plus adapté à l’écran du dispositif utilisé, par exemple en réagençant les blocs de contenus pour qu’ils s’affichent sur une colonne au lieu de plusieurs. Ceci présuppose de détecter l’ordre de lecture du document. La recherche de contenus peut être facilitée grâce à la construction de plusieurs index, se superposant au plan de classement classique. S’il est possible de transcrire les contenus (cas de l’écriture imprimée en général), alors on peut imaginer de proposer au lecteur de réaliser des recherches textuelles. Toutefois, d’autres formes d’indexations sont possibles : Eglin et al. [36] proposent de détecter le style d’écriture de certains manuscrits pour per-mettre un accès par époque. On peut également imaginer des accès par auteur, ou selon tout autre élément pertinent.
Plus généralement, la navigation peut être facilitée en produisant des regroupement d’éléments similaires, c’est à dire visuellement proches. C’est une solution à la plupart des cas où les éléments ne peuvent pas être identifiés automatiquement de façon assez fiable, ni transcrits. Eglin et al. [36] ont mis en place un système permettant de passer en revue les éléments visuels de manuscrits anciens (lettrines, enluminures), et Coüasnon et al. [27] proposent de reproduire le feuilletage en construisant dynamiquement un catalogue de mots similaires dans des registres anciens.
Coüasnon et al. [27] basent leur approche sur le concept d’annotation et proposent de distinguer : les annotations textuelles contenant des données et métadonnées relatives à une image de document (date, lieu, mots-clés, etc.) ;
les annotations graphiques correspondant à une partie de l’image (un champs de formu-laire, une cellule de tableau, une zone, etc.) représentée par un polygone ou un rec-tangle.
Ces deux types d’annotations peuvent être liés (se référencer mutuellement) pour permettre une description riche et flexible du contenu de la page. Pour produire ces annotations, Coüasnon et al. proposent un système automatique, ainsi qu’une interface de consultation qui autorise également la création et la modification d’annotations par les lecteurs.
Proposer des outils de consultation dématérialisée efficace impose donc de pouvoir identifier et interpréter les contenus pertinents dans les images des documents, et de « tra-duire », ou « transcrire » ces contenus dans un système de représentation qui puisse être exploité de façon informatique. La qualité de l’expérience de consultation est donc direc-tement liée à la finesse de l’interprétation. Cette interprétation dépend de deux éléments essentiels :
– la connaissance à propos des documents ;
– l’exploitation du contexte documentaire.
Notion de contexte documentaire
Cas de l’écriture manuscrite
Le cas du domaine de la reconnaissance d’écriture manuscrite permet d’introduire, par similarité, la notion de langage pour les documents. Les modèles de langages sont en effet utilisés pour guider et optimiser la reconnaissance d’écriture manuscrite, et ce à différents niveaux [118, 80, 82] :
le niveau morphologique qui regroupe la connaissance à propos des différents symboles ou caractères utilisés dans une langue et de leurs fréquences ;
le niveau lexical qui regroupe la connaissance à propos des mots autorisés du langage ;
le niveau syntaxique qui regroupe la connaissance à propos de la façon d’organiser les mots selon leur catégories syntaxiques (ex : « adjectif », « verbe », etc.) dans un lan-gage ;
le niveau sémantique qui regroupe la connaissance à propos des contraintes de cohérence au regard de la catégorie sémantique (aussi dite « fonctionnelle », ou « logique ») des mots (ex : « objet », « animal », etc.) ;
le niveau pragmatique qui permet de valider les propositions au regard des faits précé-demment énoncés.
Chaque niveau réduit l’espace des énoncés corrects possibles et permet de mettre en relation les parties d’un texte pour guider, vérifier, optimiser ou même compléter son interprétation. Plus le niveau d’interprétation est élevé, plus les interdépendances entre un élément et les autres sont nombreuses. L’utilisation de connaissances sémantiques et pragmatiques dans un système de reconnaissance est difficile et rare.
Le document comme langage visuel
Il est alors possible, à l’instar du langage manuscrit, de transposer ces niveaux d’abs-traction au niveau du document, voire du corpus (c’est à dire d’un ensemble de documents). C’est le constat que font Marriott et Meyer en introduction d’un ouvrage dédié à la théorie des langages visuels [74]. Un document, même textuel, peut alors comporter des zones de texte qui obéiront à un langage textuel, et on pourra considérer que les primitives visuelles, leur organisation, et les liens entre ces composants, formeront un langage visuel répondant lui aussi à des contraintes lexicales (Quels sont les objets visuels utilisés ? — texte, lignes, images, etc.), syntaxiques (Comment une page est-elle organisée ? — titres, numéros de pages, etc.), voire sémantique (Quelles sont les contraintes entre les objets représentant les numéros de pages ? — incrément d’une unité à chaque page) d’un langage visuel.
Saund [106] indique quant à lui que la validation de contraintes sémantiques (ex : la somme des prix des articles est égal au montant de la facture) ne peut être faite sans une connaissance précise de la structure du document, montrant alors l’importance d’une connaissance à priori du type de document à traiter pour extraire l’information utile.
D’autres exemples d’utilisation des liens sémantiques entre les contenus, cette fois-ci entre plusieurs pages, sont proposés par Déjean et Meunier [32] pour la reconnaissance de livres. Les auteurs exploitent certaines redondances comme celles des titres possédant une position stable en haut de page, des contraintes numériques comme l’incrémentation des numéros de pages, ou encore la cohérence dans les styles des séquences, pour optimiser l’interprétation du document. L’exploitation de ce qu’on propose d’appeler le contexte documentaire, qu’il relie des contenus à l’intérieur d’une page ou entre des pages différentes, offre donc des possibilités très intéressantes qui ne sont accessibles que si on dispose d’un modèle de document, voire de corpus, suffisamment riche.
Particularités des documents d’archives pour l’interprétation
La nature des documents anciens entraîne un certain nombre de difficultés lorsqu’on tente de les interpréter, que ce soit automatiquement, ou en proposant à un humain de les lire. Nous décrivons ici les principales difficultés liées à ces données, ainsi que les éléments favorables qui peuvent permettre d’y faire face.
Difficultés
Cette identification des difficultés liées aux documents anciens est principalement basée sur l’analyse d’Antonacopoulos et Downton [4], ainsi que sur celle d’Ogier [86].
Ambiguïté des langages humains libres
l’instar des autres formes de communication humaine, les messages portés par des documents produits par un humain peuvent rapidement devenir ambigus en l’absence de contraintes (connues) lors de la production. Pour illustrer cela, on peut prendre l’exemple d’une lettre dactylographiée : si l’auteur n’a indiqué qu’une adresse dans la lettre, est-ce la sienne ou celle du destinataire ? Qu’en est-il si deux adresses sont présentes ? Les positions relatives des deux blocs peuvent prêter à confusion.
Une analyse plus poussée du document peut permettre de trouver des éléments pour confirmer ou infirmer une hypothèse, mais ce n’est pas toujours possible.
Manque de connaissances à priori à cause du décalage historique
Le décalage temporel entre l’époque de création d’un document et l’époque actuelle est la première source de difficultés lors du traitement de documents anciens. Contraire-ment aux documents actuels, il n’est pas possible d’imposer un format que l’on maîtrise-rait, comme un formulaire prêt pour une lecture optique. On ne peut pas non plus profiter de notre connaissance sur les contraintes imposées par les logiciels de mise en page des documents modernes, qui produisent des contenus d’une grande régularité. Au contraire : selon les fonds, on peut disposer d’une connaissance très variable sur les conditions et les contraintes de productions des documents. Cette méconnaissance des techniques d’écriture, des outils utilisées, du vocabulaire, de la forme des lettres, des règles de présentation et autres usages perdus font qu’il est difficile de connaître les types de contenus et les organisations de ces derniers qui pourront être rencontrés lors de l’analyse. On peut citer le cas des patronymes, qui peuvent être obsolètes voire inconnus. Le décalage historique est donc une deuxième source d’ambiguïté dans les interprétations des documents.
Le problème d’amorçage de le connaissance d’un système de traitement de documents est alors délicat et coûteux, comme noté par Saidali et al. [105]. Ceci peut être renforcé par le besoin de faire appel à un expert du fonds documentaire considéré. Le transfert de connaissances (modèles de documents, modèles de graphèmes, lexiques, etc.) est par ailleurs délicat entre différents fonds documentaires qui présentent assez peu de points com-muns en général.
L’élaboration de modèles permettant de guider l’analyse et l’interprétation de fonds documentaires anciens est donc un processus coûteux et difficile, qui mène généralement à la production de connaissances fragmentaires à cause du décalage historique et de l’effet de l’échantillonnage de l’ensemble des données.
Altérations au cours du cycle de vie du document
Depuis sa création jusqu’à son analyse sous forme numérique, un document ancien a subi un grand nombre de perturbations qui vont altérer tant son contenu que sa structuration. La figure 1.3 illustre quelques dégradations classiques.
Lors de sa création, les auteurs d’un document peuvent faire des ratures, des tâches d’encre, et altérer dès l’origine le message à transmettre. Ensuite, le document va subir nombre de dégradations physiques au cours du temps, impactant l’intégrité du support et de l’encre, entraînant une perturbation de ses éléments structurants : courbure des traits, efface-ment de texte, traversée de l’encre entre les faces des pages, pliures, déchirures, etc. Le fait que le document puisse être annoté ou complété au cours du temps renforce ces difficultés, car l’information peut alors être étendue, altérée ou diminuée, rendant délicate la distinc-tion entre l’information pertinente et le bruit. Finalement, d’autres défauts peuvent égale-ment survenir pendant l’étape de numérisation, comme les biais, les courbures, la rognure de zones, qui contribuent à dégrader la qualité de l’information véhiculée par le média. Le stockage sous forme numérique, avec d’éventuels recadrages, compressions et autres pertes d’informations imposées par les contraintes de stockage, finit d’altérer le document.
Le rapport de stage ou le pfe est un document d’analyse, de synthèse et d’évaluation de votre apprentissage, c’est pour cela chatpfe.com propose le téléchargement des modèles complet de projet de fin d’étude, rapport de stage, mémoire, pfe, thèse, pour connaître la méthodologie à avoir et savoir comment construire les parties d’un projet de fin d’étude.
|
Table des matières
Financement
Résumé
Références de l’auteur
Table des matières
Table des figures
Liste des tableaux
Introduction
I État de l’art : Donner un environnement à l’interprétation d’images de documents
1 Interprétation de documents d’archives
1.1 Caractéristiques et utilisation
1.1.1 Typologie documentaire
1.1.2 Organisation documentaire
1.1.3 Utilisation dématérialisée de fonds d’archives
1.1.4 Notion de contexte documentaire
1.2 Particularités pour l’interprétation
1.2.1 Difficultés
1.2.2 Éléments favorables
1.3 Conclusion
2 Interprétation de documents image par image
2.1 Connaissance sous forme algorithmique
2.1.1 Approches par regroupements et par divisions
2.1.2 Approches hybrides
2.1.3 Nécessité d’un modèle de document
2.2 Connaissance sous forme statistique
2.2.1 Modèles graphiques probabilistes pour l’exploitation d’un contexte local
2.2.2 Faible structuration et acquisition difficile des connaissances
2.3 Connaissance sous forme déclarative
2.3.1 Approches semi-déclaratives
2.3.2 Approches purement déclaratives
2.3.3 Approches déclaratives extensibles
2.4 Conclusion
3 Interprétation contextuelle de fonds documentaires
3.1 Faire face à la variabilité
3.1.1 Automatiser la gestion du volume
3.1.2 Sélectionner le traitement selon le document
3.1.3 Acquérir progressivement les modèles
3.2 Tirer profit du contexte documentaire
3.2.1 Exploiter les redondances
3.2.2 Relier les données
3.3 Conclusion
4 Interprétation assistée de fonds documentaires
4.1 Traitements initiés par l’humain
4.1.1 Transfert de connaissances vers le système automatique
4.1.2 Correction libre en post-traitement
4.1.3 Correction de résultats intermédiaires et guidage
4.2 Traitements initiés par la machine
4.2.1 Correction en post-traitement des erreurs détectées
4.2.2 Adaptation grâce aux exemples
4.2.3 Correction de résultats intermédiaires
4.3 Conclusion
II Contribution : Interagir avec l’environnement grâce à une interprétation itérative
5 Architecture globale pour une interprétation itérative
5.1 Composants nécessaires
5.1.1 Base de données centrale
5.1.2 Module d’interprétation de page
5.1.3 Module de stratégie globale
5.1.4 Interfaces homme – machine
5.2 Utilisation du système global et comportement
5.2.1 Interaction avec des opérateurs humains
5.2.2 Interaction avec le fonds documentaire
5.3 Conclusion
6 Conception d’un module d’interprétation de page interactif
6.1 Communiquer avec l’environnement pour activer l’interaction
6.1.1 Modèle théorique de l’interaction
6.1.2 Fusion d’informations externes grâce à la mémoire visuelle
6.2 Formalisation d’un module de référence
6.2.1 Notion de continuation et notations utilisées
6.2.2 Formalisation des propriétés requises du module d’interprétation de page
6.2.3 Formalisation des opérations sur la mémoire visuelle
6.3 Systématiser les échanges pour corriger les erreurs
6.3.1 Mise en œuvre de l’interaction dirigée : détection automatique des problèmes
6.3.2 Garantir une progression de l’interprétation : valider questions et réponses
6.3.3 Intégration homogène de l’interaction spontanée : gérer les problèmes non détectés
6.3.4 Synthèse des opérateurs proposés
6.4 Conclusion
III Validation : Réalisation et exploitation d’un système complet
7 Réalisation d’un système complet
7.1 Vision d’ensemble du système
7.1.1 Base de donnée centrale
7.1.2 Module de stratégie globale et pilotage du système
7.1.3 Module d’interprétation de page
7.1.4 Interfaces homme–machine
7.1.5 Autres modules
7.2 DMOS-PI : une extension de l’approche DMOS-P
7.2.1 À propos de l’approche DMOS-P
7.2.2 DMOS-PI : une interprétation plus robuste
7.3 Conclusion
8 Expérimentations
8.1 Exploitation d’un contexte inter-pages et interaction dirigée
8.1.1 Description du problème
8.1.2 Scénario de référence (corrections en post-traitement)
8.1.3 Scénario interactif (regroupement et validation)
8.1.4 Protocole expérimental
8.2 Gestion de cas de sous-segmentation avec l’interaction spontanée
8.2.1 Description du problème
8.2.2 Scénario de référence (corrections en post-traitement)
8.2.3 Scénario interactif (correction spontanée)
8.2.4 Protocole expérimental
8.3 Conception et exploitation du système en conditions réelles
8.3.1 Exemple d’image complexe
8.3.2 Simplification de la conception de la description de page
8.3.3 Utilisation d’un mode d’interaction hybride
8.3.4 Comportement par paliers d’un système itératif en fonctionnement
8.4 Conclusion
IV Conclusion
9 Nouvelle approche pour l’interprétation de fonds documentaires
9.1 Contribution à l’interprétation de fonds documentaires
9.1.1 Rappel des objectifs
9.1.2 Points forts de nos travaux
9.1.3 Intérêt pour la communauté scientifique
9.2 Perspectives
9.2.1 Consolidation des propositions
9.2.2 Extension du champ d’application
Bibliographie
Télécharger le rapport complet