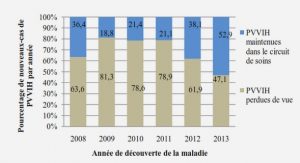
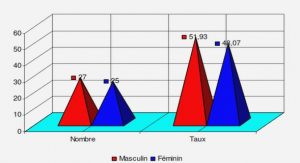
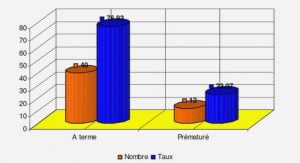
Les évolutions technologiques de ces dernières décennies génèrent une croissance importante des données. Elles sont souvent hétérogènes et présentent des liens complexes, liens qui cachent des informations implicites pouvant être importantes pour comprendre une situation. Leur exploitation devient une grande préoccupation pour les entreprises, les laboratoires de recherche et certaines entités étatiques. La croissance considérable de ce volume de données incite ces acteurs à chercher des solutions efficaces pour faciliter leur compréhension. La problématique de cette thèse concerne l’étude d’outils informatiques capables d’apporter un certain nombre de solutions axées sur la découverte d’information en s’inspirant du paradigme de l’énaction.
La découverte d’information se différencie de la recherche d’information par le fait que l’individu ne sait pas exactement ce qu’il cherche. Son questionnement sur le domaine, s’il en a un, est flou et imprécis. Selon Fayyad, la découverte d’information à partir d’une base de données consiste à développer des méthodes et des techniques pour donner un sens aux données (Fayyad, Piatetsky-Shapiro et Smyth 1996). Plus les données sont en grande quantité et présentent de nombreuses relations entre elles, plus leur exploration est complexe et demande du temps. Il est alors nécessaire d’avoir des outils dédiés. Plusieurs applications sur la découverte d’information ont été développées et ont été utilisées dans différents domaines. Des exemples de telles applications comme celle proposée par Chen et al. pour étudier les activités quotidiennes des individus dans un quartier (J. Chen et al. 2011) et celle proposée par Stab et al. qui permet de découvrir les événements qui se sont produits pendant une période de temps donnée (Stab, Nazemi et Fellner 2010). Nous considérons que les approches de découverte d’information peuvent être classées en deux catégories. La première consiste à faire des approximations de la réalité pour faire des prédictions, pour étudier des corrélations entre les variables, ou pour voir la tendance générale des données en utilisant des modèles mathématiques, statistiques ou des modèles de classifications des données. Parmi elles, nous pouvons prendre par exemple :
— des systèmes de dépannage, utilisés dans le domaine de fabrication des avions pour diagnostiquer et prédire des pannes (Fayyad, Piatetsky-Shapiro et Smyth 1996), (Lukacova, Babic et Paralic 2014) , (Matthews et al. 2013).
— des systèmes utilisés dans le domaine de l’astronomie pour analyser et classifier des images : SKICAT (Fayyad, Piatetsky-Shapiro et Smyth 1996), PhotoRApToR (Cavuoti, Brescia et Longo 2014).
— des systèmes utilisés dans le domaine du marketing pour analyser et identifier des groupes de clients, leurs comportements et les liens entre eux : Busness Week (Fayyad, Piatetsky-Shapiro et Smyth 1996), (Ngai, Xiu et Chau 2009).
La seconde catégorie est représentée par des approches exploratoires. Ces approches consistent à donner la possibilité d’accéder et d’interagir avec les données afin de déterminer les caractéristiques particulières de chacune d’elles mais également de pouvoir identifier des relations entre elles selon différents points de vues. Parmi ces approches, on peut citer par exemple :
— un système appliqué dans le domaine du marketing pour découvrir des informations sur les ventes (Piateski et Frawley 1991).
— un système d’exploration de données sur les traitements des patients (Loorak et al. 2016).
— un système d’exploration de données historiques pour découvrir l’histoire d’une ville ou d’un pays (Cho et al. 2016).
Positionnement
Dans notre travail de recherche, nous nous intéressons aux approches exploratoires
permettant de découvrir des informations et d’avoir une vision synthétique sur les relations entre les données. Pour la plupart des approches existantes, le parcours d’exploration est plus ou moins prédéfini. C’est le cas par exemple lors de la lecture des documents, la consultation de données via des sites web ou des environnements 3D (Gatalsky, N. Andrienko et G. Andrienko 2004), (Bonnel et al. 2006), (Bonis et al. 2013) et même lors de la visualisation d’informations à l’aide des graphes (Heer et Card 2004) (Jankun-Kelly et K.-L. Ma 2003). Cependant, les parcours prédéfinis risquent de perdre l’utilisateur dans une masse d’informations qui ne l’intéressent pas. Pour pallier ce problème, de nouveaux systèmes d’exploration de données sont proposés. Leur principal objectif est de personnaliser le parcours. Quelques exemples de ces systèmes sont présentés dans la section 2.2. Ils estiment les besoins de l’utilisateur selon l’historique de son parcours, son profil, voire même les avis ou les parcours des autres utilisateurs ayant le même profil que lui. Ils ne récupèrent que les informations considérées pertinentes pour l’utilisateur. Le choix des données récupérées et leur présentation dépendent alors du comportement de l’utilisateur. La problématique commune de ces nouveaux systèmes se trouve au niveau de l’estimation des besoins de l’utilisateur, ainsi qu’au niveau de la présentation des données pour que l’utilisateur ait une vision synthétique des liens entre les données.
Dans le cadre de cette thèse, notre travail se focalise sur l’utilisation du paradigme de l’énaction en tant que guide de construction de connaissances. Nous parlons de guide car il s’agit pour nous d’un point de vue original qui amène à penser d’une manière particulière une proposition d’interaction. La vision de la cognition selon le paradigme de l’énaction a été proposée par Varela, Thompson, Rosch et Maturana (Rosch, Thompson et Varela 1991). Même si elle voit ses origines en biologie, elle s’est élargie aux sciences cognitives et l’idée directrice est de considérer la co-évolution entre un agent et son environnement comme étant la base de la construction de ses représentations de cet environnement. L’agent n’est pas un récepteur passif de l’apport de cet environnement, mais est un acteur sur son environnement (Stewart et al. 2010). Son expérience dépend de sa façon d’agir. Il est en interaction avec des projections de lui même et il les modifie selon son expérience. Ces relations entre l’action et l’expérience sont façonnées par la dotation biologique de l’agent.
Ainsi, lorsqu’on parle des systèmes énactifs, quelques éléments clés sont à considérer parmi lesquels il y a l’autonomie et l’incarnation (Vernon 2010).
— L’autonomie est la capacité d’un système à se gouverner lui-même et à s’autoorganiser, selon ses propres règles. Cela signifie qu’il est capable d’opérer indépendamment de l’environnement et sans être contrôlé de l’extérieur. Pour cela, l’environnement n’est pas une entrée à traiter mais une perturbation que le système va compenser.
— L’idée de l’incarnation est que le système doit exister dans le monde en tant qu’entité physique et pouvant interagir avec son environnement. Autrement dit, le système peut agir sur les éléments de l’environnement, qui peuvent, à leur tour, agir sur lui.
La métaphore de la marche pour chemin permet d’illustrer le concept de l’énaction. Elle indique que c’est en marchant que nous créons notre propre chemin. Par exemple, un groupe de musique de jazz réagit en fonction des propositions d’un musicien. Cette réaction du groupe crée de nouvelles perceptions pour ce musicien, qui vont influencer ses prochaines interactions. Ce musicien ajuste sa façon de jouer (ses notes) en fonction des réactions des autres musiciens et de ce qu’il entend de sa musique. Nous pouvons dire alors que le groupe et le musicien co-évoluent. C’est grâce à l’expérience que les propositions de l’artiste évoluent. La « trace » laissée par cette expérience peut également influencer les prochaines créations de ses propres morceaux et devenir de nouvelles musiques.
Visualisation de données
Dans le cadre de cette thèse, l’objet de la visualisation de données est d’avoir :
— une représentation compréhensible de chacune d’elles,
— une représentation des liens existants entre elles,
— une possibilité d’interagir avec elles.
Cela permet à l’utilisateur d’identifier des informations pertinentes ou de découvrir des informations inattendues. De plus, nous nous intéressons aux outils de visualisation dédiés à l’exploration de données. Ceci écarte alors les modèles mathématiques, statistiques ou les systèmes de classification car ils ont tendance à faire disparaître les données en les remplaçant par d’autres grandeurs, ce qui ne favorise pas une exploration même si cela facilite l’analyse. Il existe plusieurs façons de classer les approches de visualisation comme par exemple suivant les types de données, les types d’interactions, le nombre de dimensions décrivant les données, ou l’objet de la visualisation. Dans notre cas, nous avons catégorisé ces approches selon les natures des relations existant entre les données.
Visualisation de données de structures ordonnées
Le fait qu’il existe des relations d’ordre entre les données (par exemple : ordre chronologique, ordre séquentiel) mène à des types de visualisation spécifiques.
Stab et al. ont proposé une approche nommée SemaTime (Stab, Nazemi et Fellner 2010) qui permet de visualiser la structure hiérarchique des données dans l’espace temporel et de montrer les dépendances sémantiques qui existent entre elles. Sur la figure 2.1, le panneau de gauche montre les différentes périodes de l’histoire, ordonnées verticalement dans le temps, le panneau central montre les différents événements correspondants à la période sélectionnée qui sont ordonnés chronologiquement dans le sens horizontal et le panneau de droite montre les descriptions des événements sélectionnés. L’utilisateur peut avoir une vue d’ensemble ou de détail sur les données en étendant ou en regroupant les niveaux de hiérarchies différents. Il peut naviguer en déplaçant le plan d’interaction horizontal. L’avantage de cette approche est qu’elle permet d’identifier les événements qui se sont passés pendant une période déterminée ou à une date spécifique donnée. Malgré l’apport important en terme d’interaction, cette approche présente des limites en termes d’exploration et de visualisation parce que pour voir les événements pendant une période, il faut d’abord savoir où se trouve cette période dans la hiérarchie. De plus, dès qu’il y a un nombre élevé d’événements dans une même période, la qualité de lisibilité des données diminue. Enfin, il est difficile de comparer des événements qui se sont produits pendant deux périodes éloignées.
|
Table des matières
1 INTRODUCTION GENERALE
1.1 Contexte
1.2 Positionnement
1.3 Organisation du mémoire
2 ETAT DE L’ART
2.1 Visualisation de données
2.1.1 Visualisation de données de structures ordonnées
2.1.2 Visualisation de données spatio-temporelles
2.1.3 Visualisation de données hiérarchiques
2.1.4 Visualisation de données multi-dimensionnelles
2.1.5 Synthèse sur les approches de visualisation
2.2 Recommandation de données
2.2.1 Approches basées sur un modèle de données
2.2.2 Approches basées sur un modèle utilisateur
2.2.3 Approches hybrides
2.2.4 Synthèse sur les approches de recommandation
2.3 Adaptabilité du système à l’utilisateur
2.4 Conclusion
3 PROPOSITION
3.1 Quelques approches sur l’exploration de données patrimoniales
3.2 Principes généraux de l’approche proposée
3.3 Description des données disponibles
3.3.1 Structures sémantiques
3.3.2 Base de données
3.3.3 Trace d’interaction
3.4 Déinition du proil utilisateur
3.4.1 Style de navigation
3.4.2 Centres d’intérêt
3.5 Recommandation de données
3.5.1 Recommandation de concepts
3.5.2 Échantillonnage de données
3.6 Incarnation de données
3.6.1 Choix de l’environnement virtuel 3D
3.6.2 Éléments constitutifs de l’environnement virtuel 3D
3.6.3 Expansion progressive de l’environnement virtuel 3D
3.6.4 Auto-organisation des informations
3.7 Conclusion
4 IMPLEMENTATION
4.1 Application dans le cadre du projet ANTIMOINE
4.1.1 Données à disposition
4.1.2 Métaphore du musée virtuel vivant
4.1.3 Éléments constitutifs du musée
4.1.4 Types d’interactions
4.1.5 Applications implémentées
4.1.6 Architecture logicielle
4.1.7 Exemple de scénario d’exploration
4.2 Application à d’autres types d’interfaces
4.2.1 Interface 2D
4.2.2 Interface immersive
4.3 Application à un autre domaine
4.4 Conclusion
5 CONCLUSION GENERALE
![]() Télécharger le rapport complet
Télécharger le rapport complet